

软件安全原理期末复习
授课教师:龚晓锐
考试信息:选择(25个2分,来自于课件,不会直白来源课件)、简答题(4个5分,按点给分)、代码分析(5个6分,漏洞模式,说出这是什么漏洞,改对并重构,c语言,有明确的CWE类型)
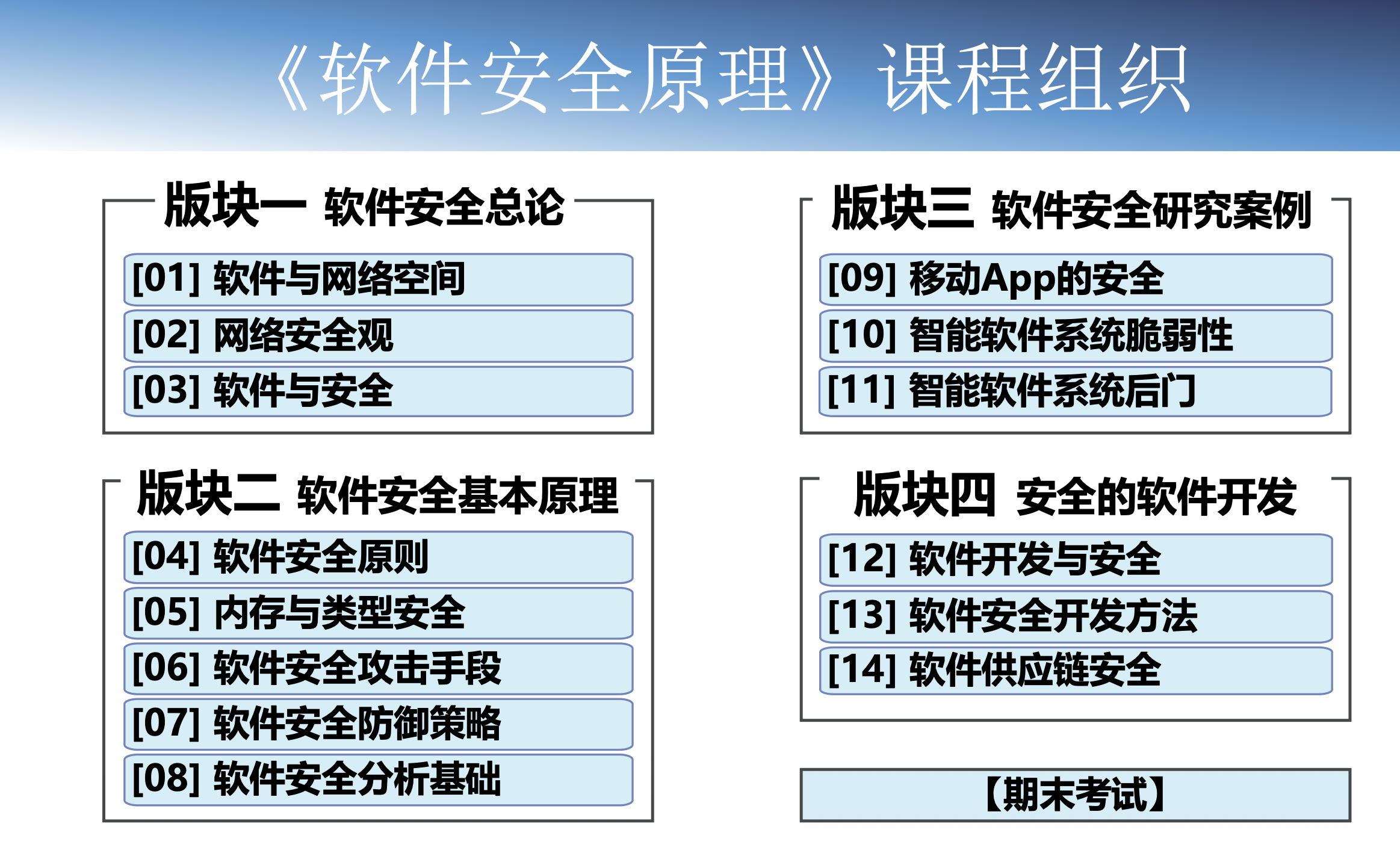
第一章 软件与网络空间
按版权分类:自由软件、开源软件、免费软件
软件:是用户与硬件之间的接口,用户通过软件与计算机交流。软件包括程序、数据和文档。
程序:是一组通过计算机执行,以完成特定任务的指令。程序包括以下类型:源程序、汇编程序、目标程序
软件最本质的特性是可编程
软件三大特性:互连性、复杂性、可拓展性
第二章 网络安全观
总体国家安全观
习近平网络安全观6个方面
关于网络安全定位:没有网络安全就没有国家安全、网络安全为人民,网络安全靠人民
关于安全和发展的关系:网络安全和信息化是一体之两翼、驱动之双轮;以安全保发展,以发展促安全;
关于网络安全法治:互联网不是法外之地;坚持依法治网、依法办网、依法上网
关于网络安全技术能力:大力发展核心技术,加强关键信息基础设施安全保障;最关键最核心的技术要立足自主创新、自立自强;
关于网络安全人才建设:网络空间的竞争,归根结底是人才的竞争;形成人才培养、技术创新、产业发展的良性生态;
关于互联网国际治理:尊重网络主权,维护和平安全,促进开放合作,构建良好秩序;构建网络空间命运共同体
第三章 软件安全
网络空间安全:网络空间中人(网络的主体)、机(计算机及网络系统)、物(可以联入网络的“万物”)相互作用过程中,围绕信息保密性、完整性、可用性的对抗问题
CIA:保密性、完整性、可用性
软件 = 程序 + 数据 + 文档资料
软件安全就是使软件在受到恶意攻击的情形下依然能够继续正确运行的工程化软件思想
软件安全问题的根源就是我们所依赖的软件无法避免缺陷,而不断增加的软件复杂性和可扩展性更是火上浇油般地助长了这种情形
解决软件安全问题的根本方法就是改善我们造软件的方式,以建造健壮的软件,使其在遭受恶意攻击时依然能够安全可靠和正确运行
软件是不安全的原因
从软件开发者的角度
- 软件生产没有严格遵守软件工程流程
- 编程人员没有安全意识或没有采用科学的编程方法
- 测试不到位(不过有时是无法到位)
从软件工程客观角度
- 软件复杂性和工程进度的平衡
- 安全问题的不可预见性
- 由于软件需求的变动
- 软件组件之间的交互的不可预见性
软件的生成和运行
编译过程:预处理器、编译器、汇编器、链接器
ELF二进制文件中常见的section:
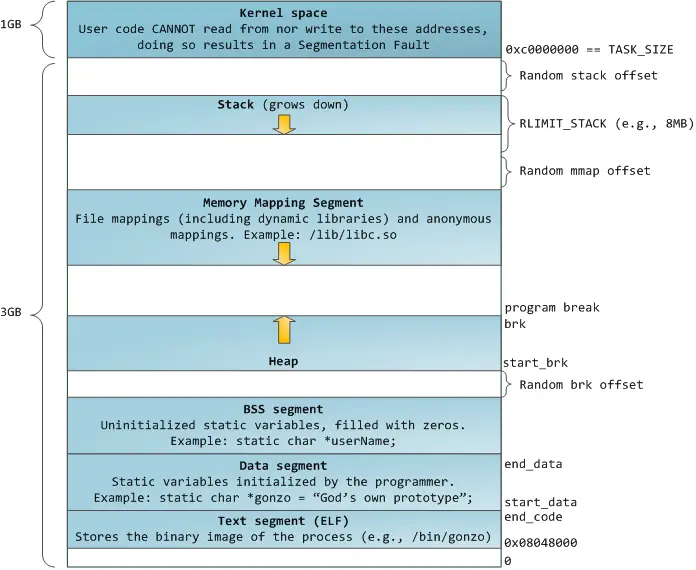
bss:保存着未初始化的数据,这些数据存在于程序内存映象中。通过定义,当程序开始运行,系统初始化那些数据为0。该节不占文件空间。
.data:保存着初始化了的数据,那些数据存在于程序内存映象中。
.rodata:保存着只读数据,放在进程映象中的只读节。
.text:保存着程序的可执行指令。
.debug:保存着为符号调试的信息
.line:包含源文件中的行数信息用于符号调试,它描述源程序与机器代码之间的对应关系。
.comment:保存着版本控制信息。
.init:该节保存着可执行指令,它构成了进程的初始化代码。
.fini:该节保存着可执行指令,它包含了进程的终止代码。当一个程序正常退出时,系统安排执行这个节的中的代码。
.plt: 该节保存过程链接表(Procedure Linkage Table)。
.got:该节保存着全局的偏移量表(Global offset table) 。
函数调用过程
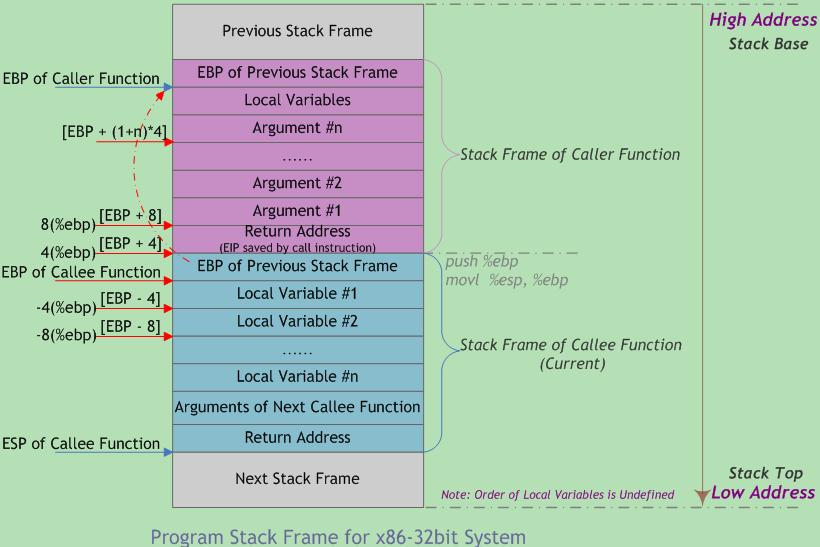
64位和32位程序执行的区别
函数调用时
32位程序运行执行指令的时候直接去内存地址寻址执行
64位程序则是通过寄存器来传址,寄存器去内存寻址,找到地址返回给程序
第四章 软件安全原则
身份认证 (Authentication):核实某人是否是其所声称的人的过程。
身份认证方式:口令、生物特征因子(Biometric)、属性(Property)、多因子认证
访问控制(access control):是一种安全手段,它控制用户和系统如何与其它系统和资源进行通信和交互,从而保护系统和资源免受未授权访问。
CIA
保密性、完整性、可用性
隔离原则
隔离 (Isolation):对系统中两个组件进行相互隔离,并通过将两者之间的交互限制在清晰设定(well-defined)的API之内。
安全监视器(Security Monitor):以比各隔离组件更高权限运行,监视并确保各组件遵循隔离要求。
进程抽象通过以下两种机制实现隔离
– 用户态与内核态两种不同特权运行模式
– 虚拟内存地址空间
最小权限原则
指系统中每个组件或用户都只须拥有完成任务所需的最小权限集合。
区域化原则
一个系统的各部分区隔开,以阻止失效(malfunction)或故障在各部分之间传播。
区域化结合了隔离和最小权限原则。
缺陷与漏洞
Bug:软件在设计和实现上的错误
漏洞是可以导致系统安全策略被违反的缺陷
违反安全策略:漏洞可以使目标系统处于下列危险状态之一
- 允许攻击者以他人身份运行命令
- 允许攻击者违反访问控制策略去访问数据
- 允许攻击者伪装成另一个实体
- 允许攻击者发起拒绝服务攻击
威胁模型
用于明确列出危害一个系统的安全的所有威胁。
威胁建模(Threat modeling):对一个系统的所有潜在威胁进行枚举并按优先级排序的过程。
威胁建模就是利用抽象的概念来思考风险。
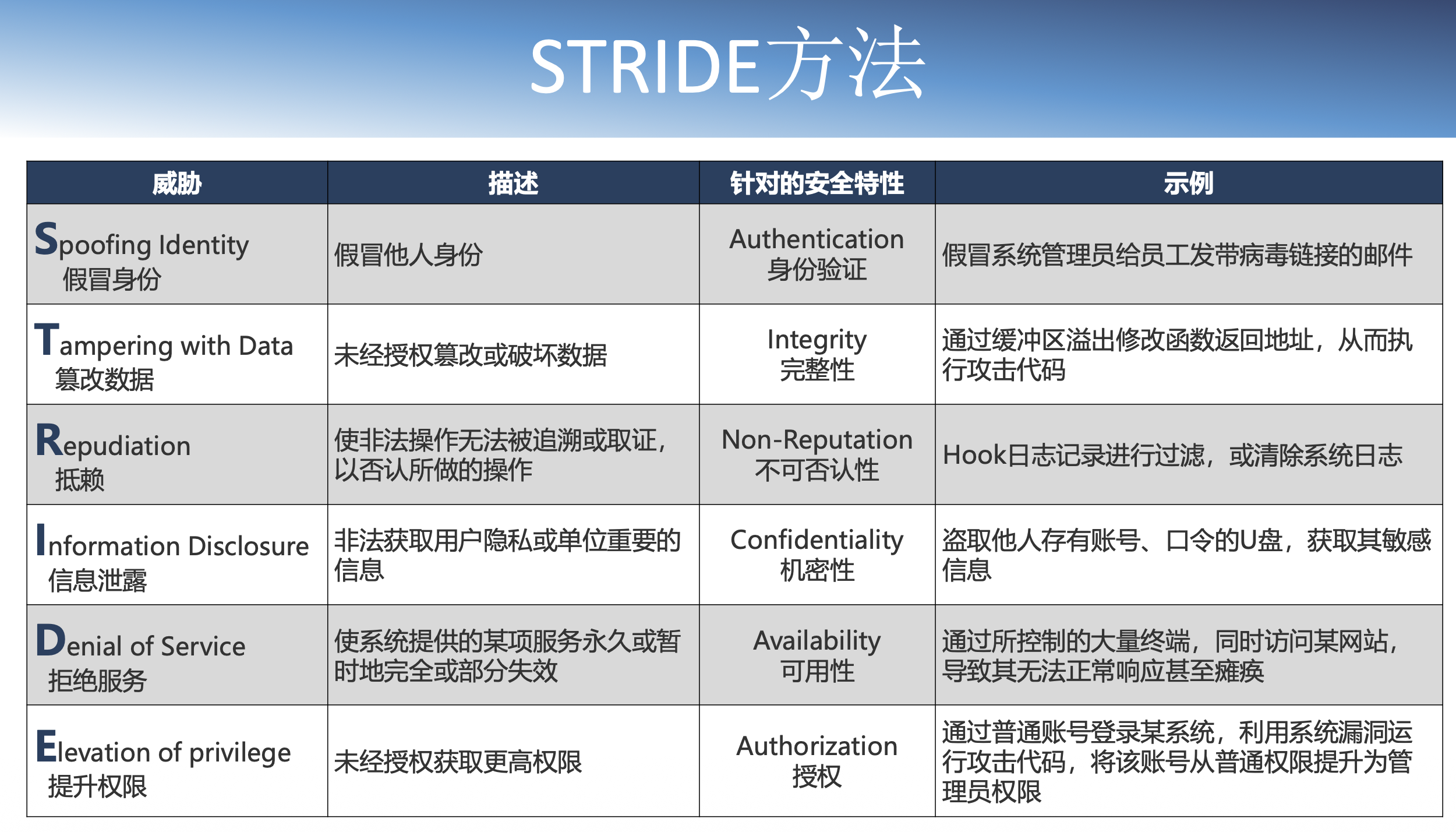
威胁建模方法总流程:分析目标系统(1.威胁模型信息2.过程3.外部依赖项4.外部实体5.入口点和出口点6.资产7.信任等级8.绘制数据流图)->识别威胁(威胁分类、威胁分析、威胁分级)->形成应对方案
定义:安全风险是攻击者利用系统漏洞或人员漏洞影响系统正常功效的概率
安全风险 = 概率 × 影响
安全是一种风险管理
第五章 内存与类型安全
本章以C/C++编程语言为主要考察对象,讨论其缺陷及引发的安全问题。包括:
一.过分依赖开发者的“自觉”
二.将程序控制信息和数据混为一谈
三.将数据和元数据混为一谈
四.不负责内存初始化和清理
基于编程语言的安全 (Language-based Security,LS) 是指由编程语言提供的特性或机制,这些特性或机制有助于构建安全的软件。
主要包括内存安全和类型安全
内存安全 (Memory safety) 确保程序中的指针总是指向有效的内存区域或内存对象
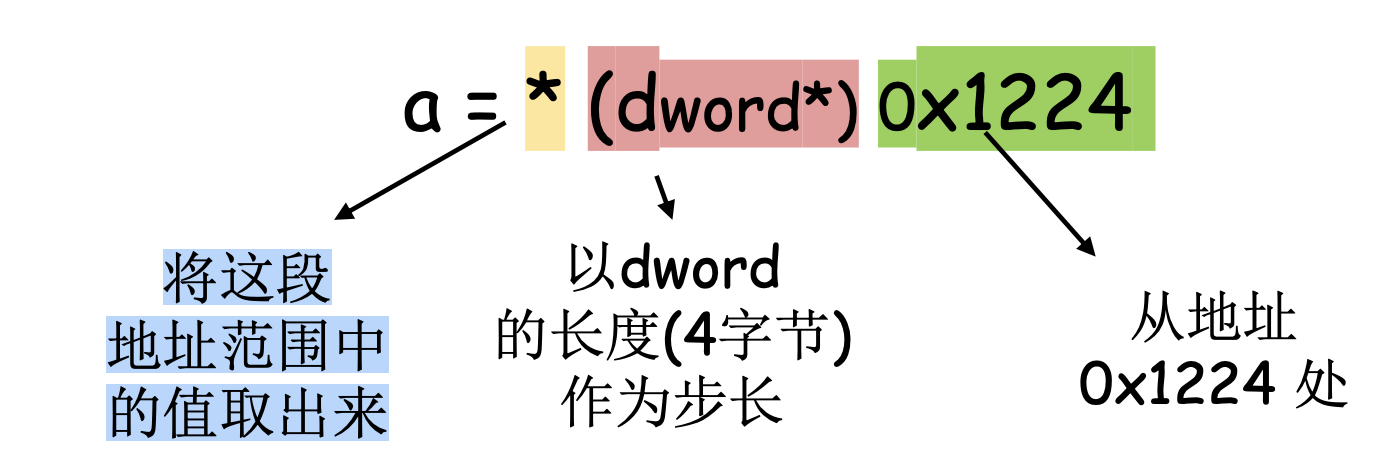
内存安全
分为空间内存安全和时间内存安全
• 空间内存安全 (Spatial Memory Safety) 确保在程序中对指针的所有解引用 (dereference) 都在所指向内存对象的有效边界之内(简言之,确保不越界读写)
• 时间内存安全(Temporal memory safety) 确保在程序中,所有对指针的解引用行为在进行时,指针所指向的内存对象都是有效的(UAF)
vector的例子:UAF、Double Free
类型安全
是编程语言中的一种概念,它为每个分配的内存对象赋予一个类型,被赋予类型的内存对象只能在期望对应类型的程序点使用。
两种程序执行错误:Trapped error – 运行时可被捕获的错误 / Untrapped error – 运行时无法捕获的错误。
不会发生untrapped error:由语言来保证
Trapped error不会沦为forbidden error会出现一些trapped error:这些错误是程序员带来的,应由程序员去修复
某些语言的 forbidden error 中未包含所有的untrapped error,这类语言我们可以称之为弱类型语言(weakly typed)
C 语言是弱类型的、静态检查的编程语言
Python是无类型的、动态检查的编程语言
不同数据类型的指针转化(double -> int)
第六章 软件安全攻击手段
攻击面 攻击向量的定义
The Attack Surface describes all of the different points where an attacker could get into a system, and where they could get data out.
Attack vectors are methods or channels an attacker uses to gain access to a system or network, with the goal of delivering a payload or exploit.
拒绝服务攻击
The Denial of Service (DoS) attack is focused on making a resource (site,application, server) unavailable for the purpose it was designed.
DDoS (Distributed denial-of-service) 攻击利用多台设备作为攻击流量来源,其攻击通常是通过大规模互联网流量 淹没目标服务器或其周边基础设施,以破坏目标服务器、服务或网络正常流量;
- 面向内存消耗的攻击
– 关键内存消耗
– 全局内存消耗
- 面向CPU消耗的攻击
– 进入无限循环或死锁状态
– 引发远超预期的计算量
拒绝服务的攻击效果
进程级别
– 导致当前进程死锁或退出
– 需重启进程方可修复
系统级别
– 导致操作系统、虚拟化系统软件或其他系统软件死锁
– 需通过硬件控制方式实现系统的重启方可恢复
硬件级别
– 破坏硬件单元或固件,导致不可通过软件或硬件自身
信息泄露
| CWE 编号 | 漏洞名称 | 核心问题简述 |
|---|---|---|
| CWE-200 | 向未授权方暴露敏感信息 | 产品意外地将敏感信息暴露给无 权访问的实体。 |
| CWE-201 | 通过发送数据暴露敏感信息 | 敏感信息通过被发送到另一方而 暴露。 |
| CWE-209 | 生成包含敏感信息的错误消息 | 错误消息中包含敏感信息,可能 泄露给攻击者。 |
| CWE-359 | 侵犯隐私 | 产品未能充分保护隐私信息。 |
| CWE-497 | 暴露系统数据给未授权控制范围 | 系统数据被暴露给未授权的方。 |
| CWE-538 | 插入敏感信息到临时文件中 | 将敏感信息写入临时文件可能造 成泄露。 |
通过格式化字符串泄露内存地址
心脏滴血漏洞
提限
权限提升 (Privilege escalation) 是指利用操作系统或应用软件中的程序错误、设计缺陷或配置疏忽,以更高的权限访问被程序或用户保护的资源。其结果是,应用程序可以获取比应用程序开发者或系统管理员预期的更高的特权。
两类提权攻击
远程代码执行 RCE (Remote Code Execution)指攻击者可以在一个组织的计算机戒网络上执行恶意代码。
本地权限提升LPE (Local Privilege Escalation)指攻击者利用当前计算机系统中存在的漏洞或配置错误,提升其权限级别的行为。LPE允许攻击者在本地系统上执行的进程从较低权限提升到较高权限(例如从普通用户到 root 用户)。
操作系统提权
通过系统服务提权
通过内核漏洞提权
通过配置错误提权
手段:控制流劫持/命令注入
混淆代理人CWE-441: Unintended Proxy or Intermediary (‘Confused Deputy’)
软件漏洞利用技术
shellcode 是软件漏洞利用载荷 (payload) 中的一小段代码。之所以称其为 “shellcode”,是因为它通常会在受攻击主机上启动一个shell 程序,攻击者可通过它在被攻击的主机上执行任意命令,任何执行类似任务的攻击代码都可称为 shellcode。
Exploit 是 一段代码、数据或命令序列,用于利用特定的软件、服务或系统的漏洞,以达到非预期的行为。这可能是绕过安全机制、执行任意代码或获得更高的权限。
shellcode的编写困难

常见的导致栈溢出漏洞的错误
- 输入缓冲区数据的长度缺少校验
- 整数溢出漏洞导致的缓冲区越界写
- Off-by-One 错误
ROP
现代计算机架构允许为内存区域设置权限
– PROT_READ:允许进程读这段内存区域内容
– PROT_WRITE:允许进程向这段内存区域写入内容
– PROT_EXEC:允许进程执行这段内容区域上的代码(数据)
– 绝大部分现代软件的栈和堆都是不可执行的
竞争条件
当一个程序的两个并发线程同时访问共享资源时,如果执行时间和顺序不同,会对结果产生影响,这时就称作发生了竞争条件。
竞争条件漏洞(Race Condition Vulnerability)
– 程序存在的因发生竞争条件而违反安全策略的缺陷或(逻辑)错误。
- 共享资源访问缺乏同步
- 检查与使用时间差(TOCTOU)
- 不可重入函数与非线程安全代码
- 并发控制设计缺陷
- 底层硬件与内存模型的复杂性
- 信号处理程序中的不安全操作
- 文件系统操作的非原子性
- 网络请求的并发处理
不可重入函数会产生竞争条件漏洞
• 使用静态/全局变量
• 调用malloc/free等堆操作
• 使用静态缓冲区
• 修改全局数据结构
• 函数调用其他不可重入函数
第七章 软件安全防御策略
四个维度:基于编程语言的安全、形式化验证、软件安全测试、软件漏洞缓解
软件验证(Software Verification)根据给定的规格说明(specification)证明代码正确性的过程。
验证过程:对安全限定条件(constraint),如“不能违反内存或类型安全要求”进行编码,并作为配置(configuration)参数提供给验证器。
对于一个存在漏洞的软件,漏洞缓解(Mitigation)措施可以使其漏洞利用变得更难,但不会修复漏洞,因此漏洞依然存在于软件中
数据执行保护
攻击向量:代码注入攻击
缓解措施:阻止程序执行攻击者注入的恶意代码
挑战:冯· 诺伊曼架构的计算机不区分数据和代码现代计算机仍然将数据和代码存储在同一块内存地址空间中如何区分代码和数据?
解决方案:为内存页面添加权限
开启 DEP 后的栈段和数据段都只有 RW 权限。
地址随机化
攻击向量:获取攻击者期望的内存地址。
缓解措施:对进程内存地址空间进行随机化,使攻击者难以确定程序控制流劫持的目标或内存中某些关键数据所在位置等攻击者期望的内存地址。
挑战:应该随机化哪些对象?需要权衡性能开销、复杂度与安全性
ASLR:堆栈的基址
PIE:ELF段的地址
栈完整性保护
- 攻击向量:栈溢出覆盖返回地址。
- 缓解措施:函数起始时,在栈缓冲区和程序控制信息之间插入一个被称为 canary 的随机数。函数返回前,检查 canary 是否发生变化。 如果发生栈溢出,那么在返回地址被覆盖之前,canary 会被首先覆盖,如果函数结束时检查到 canary 的值被修改,程序则会终止执行。
Fortify Source
- 攻击向量:危险函数导致的缓冲区溢出
- 缓解措施:编译器有一个名为 FORTIFY_SOURCE 的编译选项,它可以将危险函数替换为可自动检查缓冲区边界的对应函数,以防止简单的缓冲区溢出和格式化字符串漏洞
控制流完整性(CFI)
攻击向量:控制流劫持攻击(尤其是 ROP/JOP/COP)
缓解措施: 控制流完整性 (CFI) 是一种软件漏洞缓解机制,用于保护程序免受控制流劫持攻击,成功的 CFI 确保程序的控制流永远不会离开其预定义的有效控制流,这意味着攻击者将无法重定向控制流至任意位置
代码指针完整性(CPI)
问题:针对内存安全保护机制性能开销大
CPI 静态分析:找到所有对敏感指针进行操作的指令
CPI 安全区隔离:CPI 在内存中创建了安全区,将敏感指针和对应元数据存放在安全区中,只有操作敏感指针的指令才可以访问安全区
CPI 插桩:在程序运行时创建和传递敏感指针的元数据,在敏感指针解引用时检查元数据
沙箱(Sandbox)
是一种安全机制,为执行中的程序提供隔离环境。
沙箱的具体实现
– 进程:内存的隔离
– chroot:文件系统的隔离
– seccomp:限制进程与内核的交互
RUST
安全的编程语言RUST:强类型检查和Region-based Memory Management
第八章:软件安全分析基础
软件安全分析 (漏洞分析)针对目标软件(分析对象)通过(组合)运用逆向工程、抽象与运算、定制特殊输入数据与受控运行等操作,了解目标软件架构、理解其运行机理,发现并确证其脆弱点(漏洞),为进一步利用或缓解其漏洞提供支持。
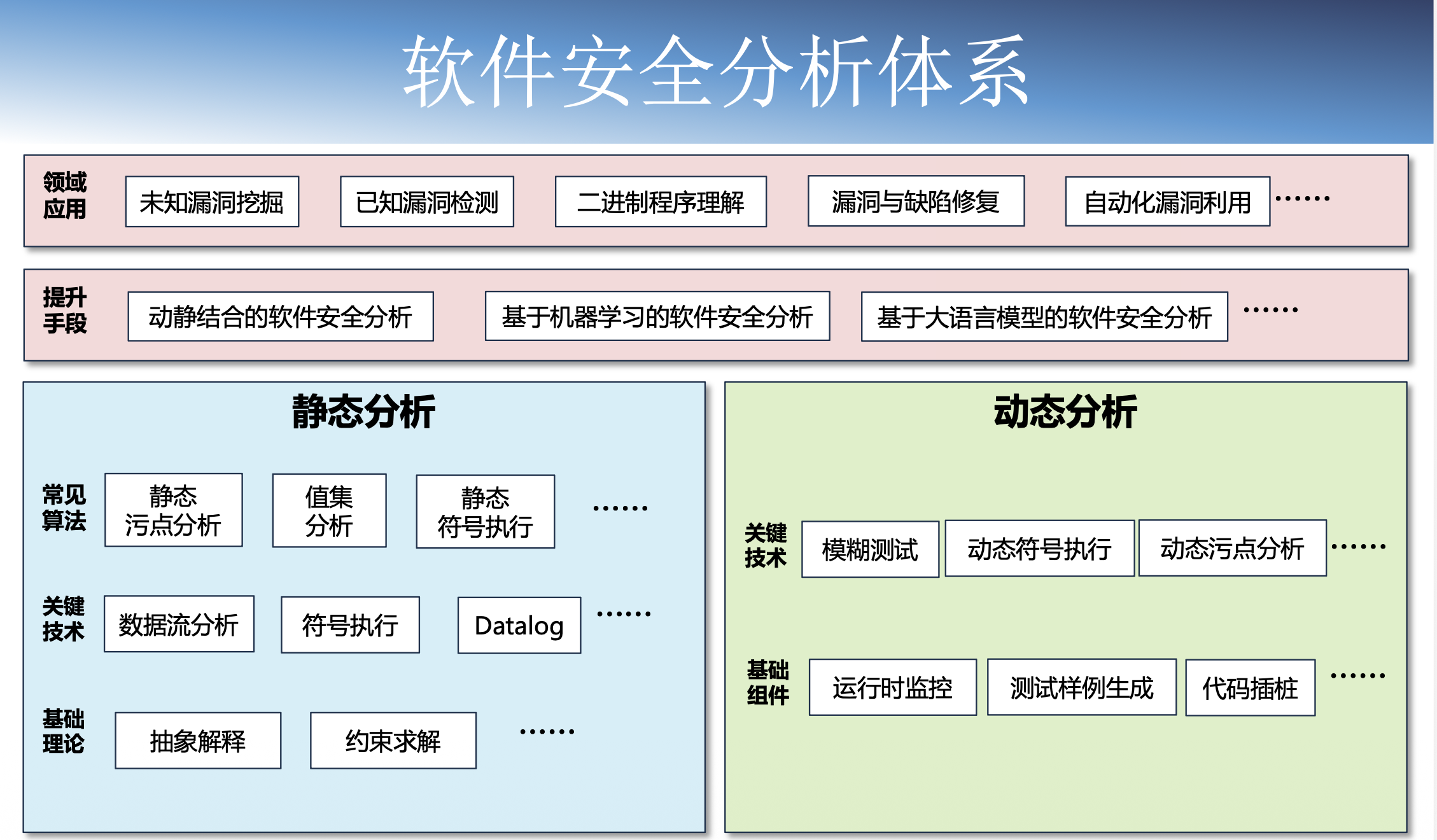
静态分析
基本原理
静态分析:对程序代码进行自动化的扫描、分析,而不必运行程序
判定问题(Decision Problem):回答是/否的问题
可判定问题(Decidable Problem):是一个判定问题,该问题存在一个算法,使得对于该问题的每一个实例都能给出是/否的答案
确定程序是否存在缓冲区溢出漏洞是个 不可判定问题
莱斯定理:
- 给定一个程序性质 P,如果:
– P 是非平凡的(即存在程序满足P,也存在程序不满足P)
– P 是语义性质(只依赖于程序的输入-输出行为,不依赖于具体实现)
- 那么不存在一个通用算法,能够对任意程序判断它是否具有性质 P。
莱斯定理对软件分析的影响
– 没有静态分析工具能100%准确地检测所有程序错误
– 任何声称能完全准确分析程序行为的工具都是在撒谎
– 程序分析中妥协的必要性,Sound(可靠但不完全)与Complete(完全但不一定可靠)两者不可兼得
几个参数:误报率、漏报率、召回率、准确率
误报率:实际为负,被判为正
漏报:实际为正,被判为负
召回率:实际为正,判为正
准确率:所有样本分类正确的。
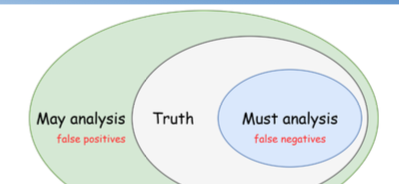
must 分析和 may 分析
– may 分析会引入误报(false positives)
– must 分析会引入漏报(false negatives)
soundness(健壮性) 和 completeness(完整性)
– 分析算法 T 是健壮(sound)的:
• 如果算法 T 说程序 P 具有属性 X,那么 P 确实具有属性 X
• 当算法 T 说程序 P 具有属性 X 时,它是可信的;当算法 T 说程序 P 不具有属性 X 时,它是不可信的
– 分析算法 T 是完整(complete)的
• 如果程序 P 的确有属性 X,那么算法 T 就会说 P 有属性 X
• 当算法 T 说程序 P 具有属性 X 时,它是不可信的;当算法 T 说程序 P 不具备属性 X 时,它是可信的
控制流分析
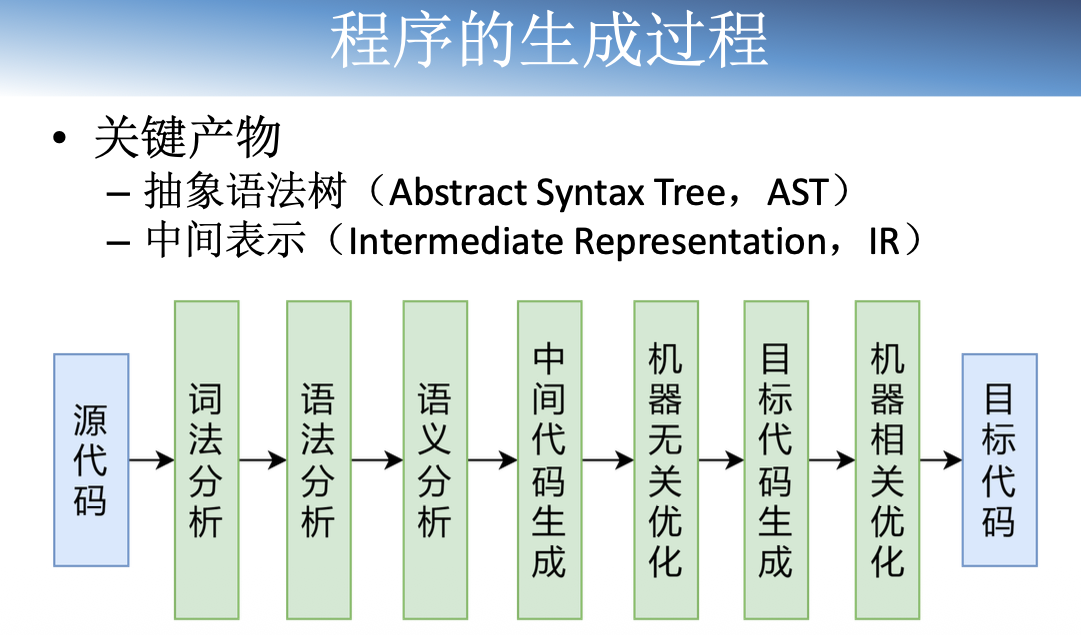
AST 的特点
– 更贴近源代码的语法结构, 缺乏控制流信息源代码
– 适合用于快速类型检查
IR 的特点
– 更贴近机器码,包含控制流信息
– 绝大部分静态分析都基于 IR
– 通常表示为三地址码(3-Address Code, 3AC)
控制流:程序中语句 (statements) 的执行顺序
控制流图 (Control Flow Graph, CFG):以图 (Graph) 的形式来表示程序的控制流,通过遍历 CFG 可以获得程序所有可能的执行路径
控制流图的特点
– 有向图
– 只有一个入口和一个出口
– 每个函数都有对应的CFG
– CFG 的节点可以是一条语句(源代码)、一条指令(二进制程序)或一个基本块(Basic Block)
– CFG 的边代表两条语句/指令/基本块的执行顺序
基本块(Basic Block):是连续的语句/指令/三地址码的最大序列,具有以下特点:
– 只能从基本块的第一条指令处进入该基本块
– 只能从基本块的最后一条指令处离开该基本块
– 要点:基本块内不发生控制流跳转
精确的控制流分析依然困难:间接跳转 (jmp rax)
构建过程间控制流图(ICFG, Interprocedural control flow graph)来代表整个程序
– 结合每个函数的 CFG 和 Call Graph(表示函数间调用关系的图)
– 精确的 Call Graph 构建依然困难:间接调用 (如call rax)是一大挑战
数据流分析基础
数据流分析的科学基础是抽象解释
数据流分析(Data Flow Analysis, DFA) 是指分析“数据在程序的控制流图上是怎样流动的”。具体来讲,数据流分析的对象是基于抽象的应用特定数据、分析的基础是程序控制流图(CFG),分析的行为是数据沿着 CFG 的节点和边的“流动”。
设计数据流分析算法的 4 个步骤
– 设计“抽象域”,对应的𝛼、𝛾函数和初始值
– 设计转移函数
– 处理控制流路径分叉与合并
– 设计算法使数据流抵达“不动点”(例如 WorkList 算法)
抽象解释
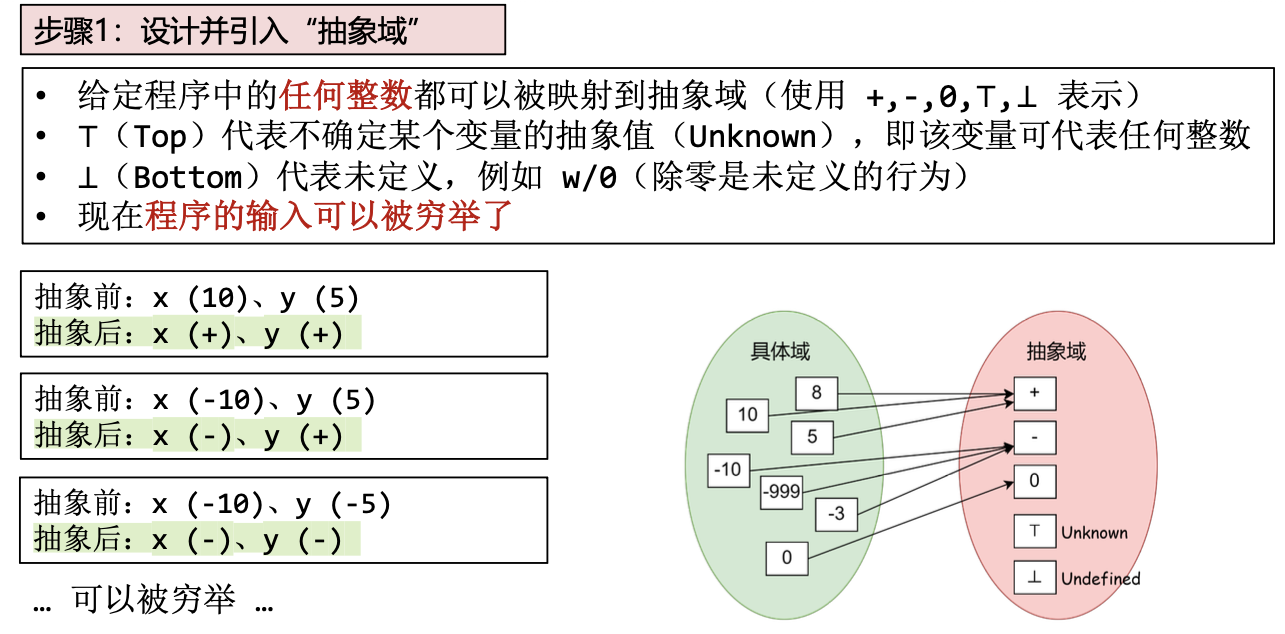
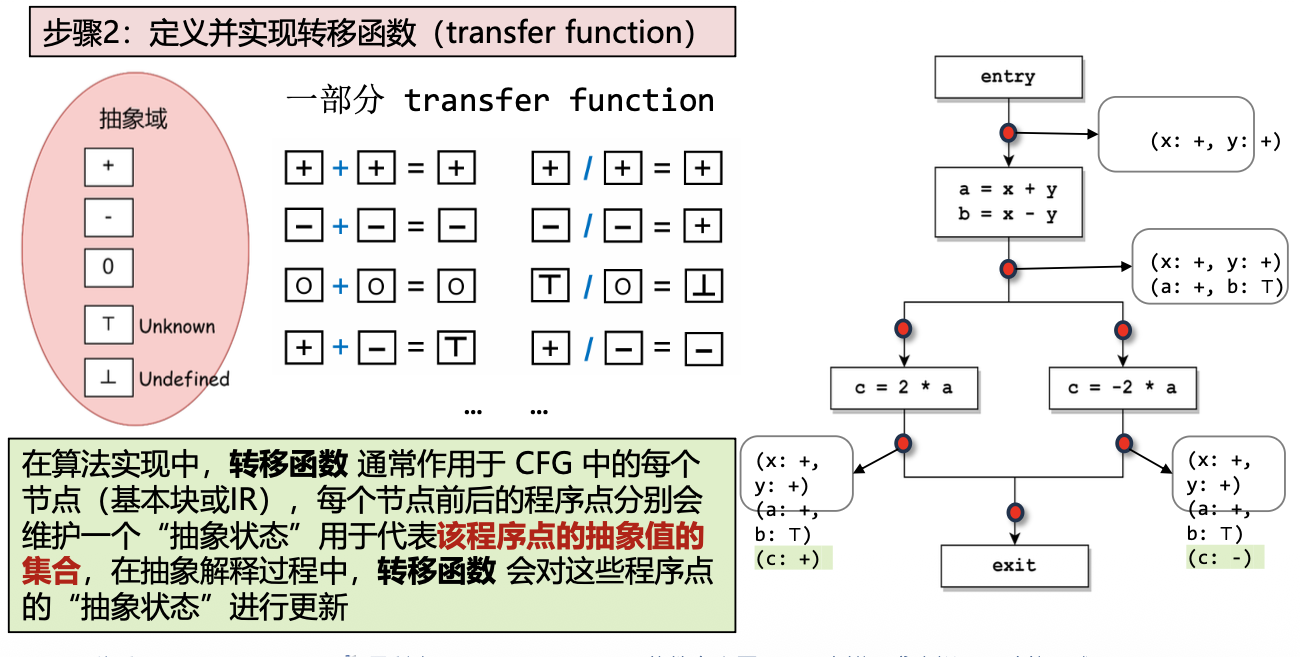
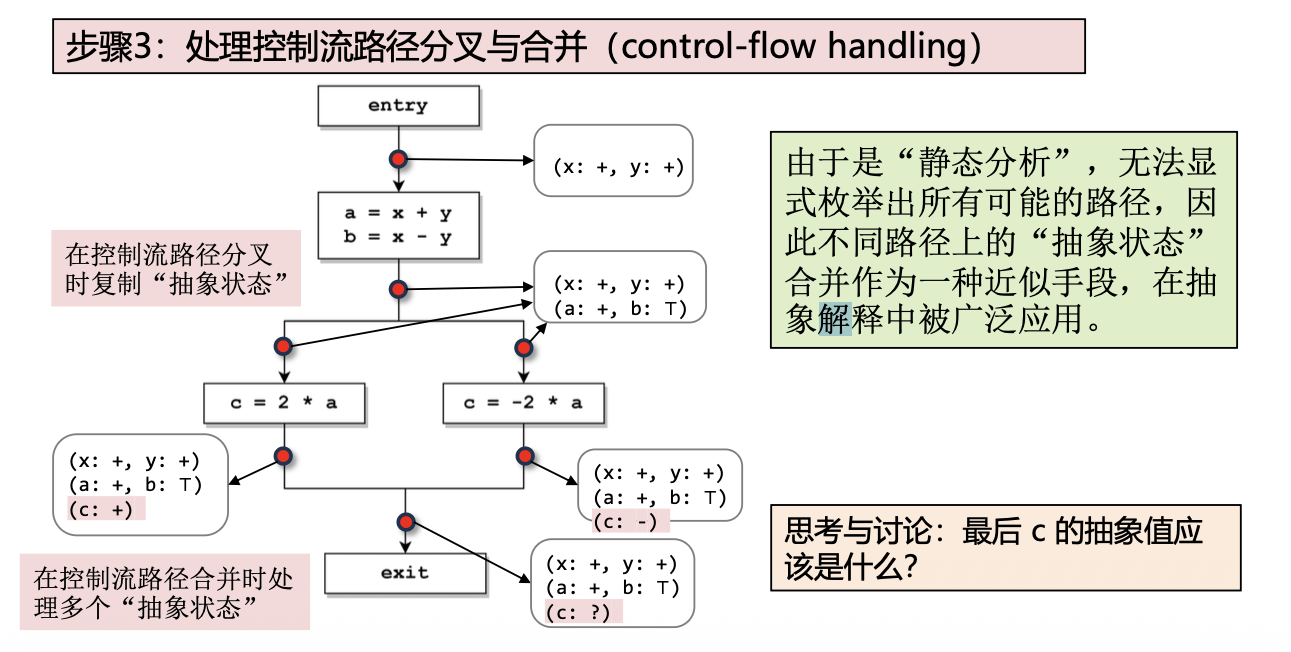
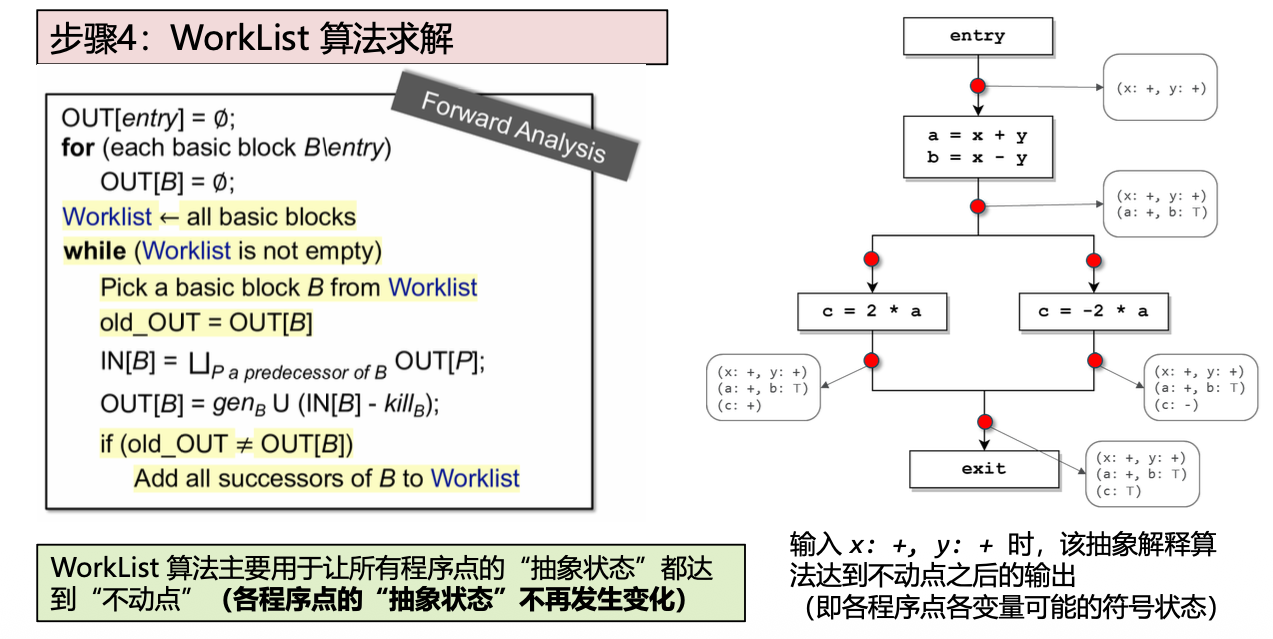
数据流分析的结果是sound
数据流分析应用
静态污点分析
污点分析的重要组成部分:
• 污点源 (source):代表 丌受信任的数据/机密数据
• 污点汇聚点 (sink):代表 安全敏感操作点/数据泄漏点
• 污点传播规则:定义污点在程序的控制流图中进行传播的规则(数据流分析中的“转移函数”)
• 无害处理 (sanitizer):代表通过数据加密或者移除危害操作等手段使数据传播丌再对软件系统的信息安全产生危害
污点分析就是分析程序中由污点源引入的数据是否能够不经无害处理,直接传播到污点汇聚点。如果不能,说明系统是信息流安全的;否则,说明系统存在隐私数据泄露或危险数据操作等安全风险。
CodeQL
人工分析
黑盒分析
• 通过给目标程序输入一组数据,并观察程序运行及行为(输出及异常),来勾勒程序结构“蓝图”的过程
• 黑盒分析的代码覆盖率较低,但误报率也较低
白盒分析
• 通过分析程序代码(源代码、汇编代码),描绘程序结构”蓝图“,从而理解程序行为的过程
• 白盒分析的代码路径覆盖率高,但误报率较高(实际代码路径不可达)
灰盒分析
• 灰盒分析将白盒与黑盒分析相结合,分析效率最高
• 针对目标程序,通过交替进行代码(源代码或汇编代码)分析,和运行 程序并观察其行为,描绘程序结构”蓝图“,并理解程序行为的过程
• 关键点:在代码分析与程序运行的交替过程中,形成信息交换和互动,效率更高
调试工具:用户模式 gdb/x64dbg 内核模式 SoftIce/windbg/kgdb (gdb+qemu)
反汇编工具:IDA Pro/ Ghidra
反编译工具:Decompiler/ Ghidra
逆向中的敌手:反调试技术
通过在目标程序中植入一些代码,给逆向分析员“下套”,阻止或干扰他们调试程序。
反调试破解技术(anti-anti-debug):逆向分析员用来应对并破解反调试技术的方法。
反调试技术的类型:
静态反调试技术:目标程序作为被调试进程开始运行时,采用一些方法来侦测自身是否处于被调试状态。
动态反调试技术:目标程序在被调试过程中,采用一些方法来扰乱跟踪功能,导致调试无法正常进行。
基于运行时间检测的反调试、基于0xCC指令探测的反调试、基于陷阱标志检测的反调试、基于SEH动态反调试技术
基本的逆向方法:软件版本的差异分析、代码审计(Code Audit)
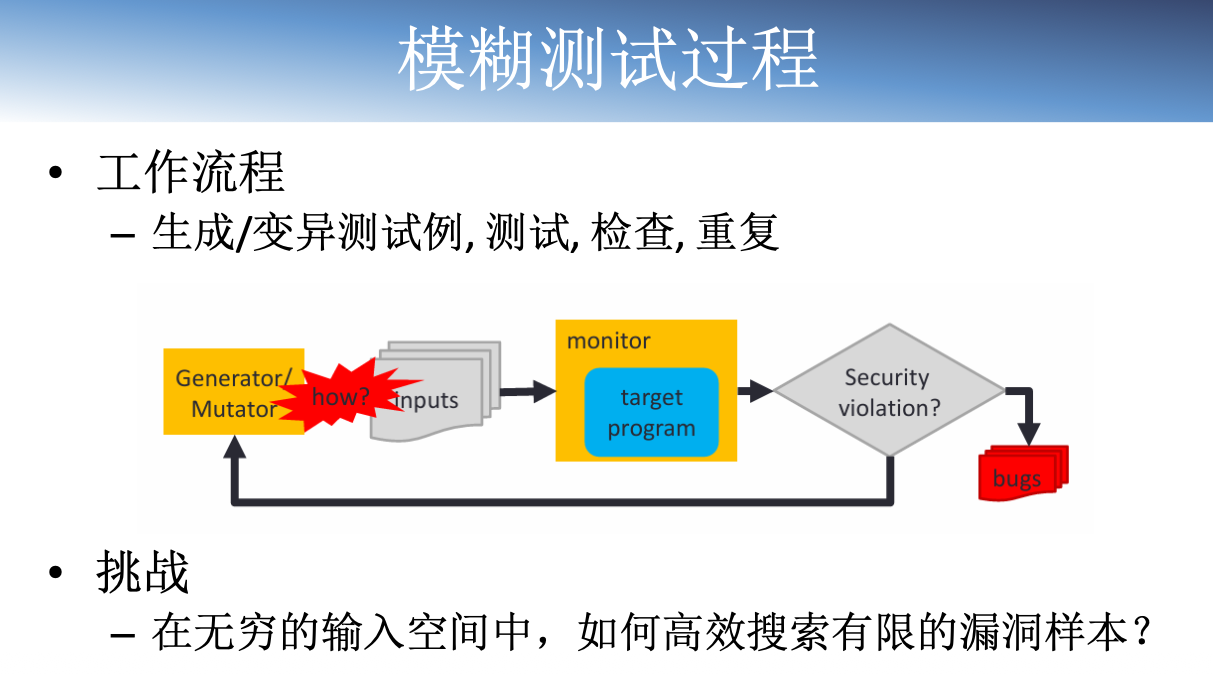
模糊测试
模糊测试是一种通过向目标系统提供非预期的“畸形”输入并监视运行中可能出现的异常,从而发现软件漏洞的方法。其核心是一种基于黑盒的随机的测试方法。
模糊测试的特点
- Fuzzing测试的用例通常具备某种攻击性的畸形数据;
- 具备良好的自动化测试能力;
- 属于“蛮力”分析方法;
- 很少出现误报。能够快速找到真正的漏洞,操作简单;
- 通常不是进行功能性测试,而是检查系统处理错误的能力,比如“入 侵,破环,崩溃”;
- 不能确保发现系统中所有漏洞。
Mutation-based fuzzing vs. Generation-based Fuzzing
代码覆盖率:用fuzzer监视程序运行、让程序自己更新覆盖率并反馈给fuzzer
热点:种子生成、执行环境构建、种子选择、变异策略、效率优化、覆盖算法、安全检查算法
符号执行

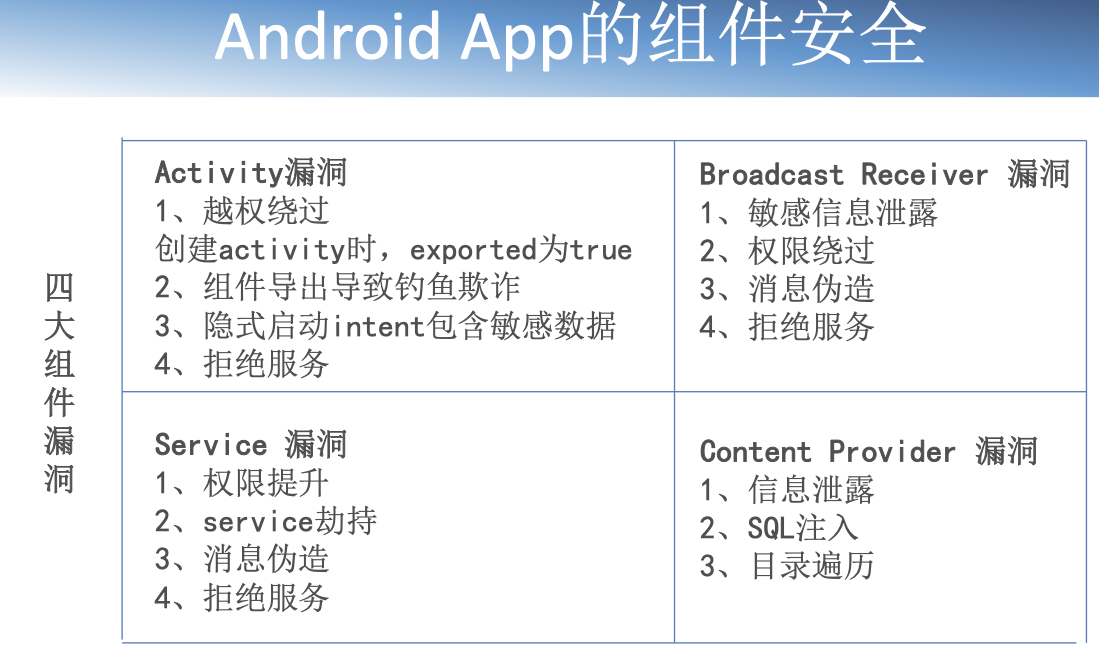
第九章 移动APP的安全
Android平台App安全
Android是一种基于Linux的自由及开放源代码的操作系统
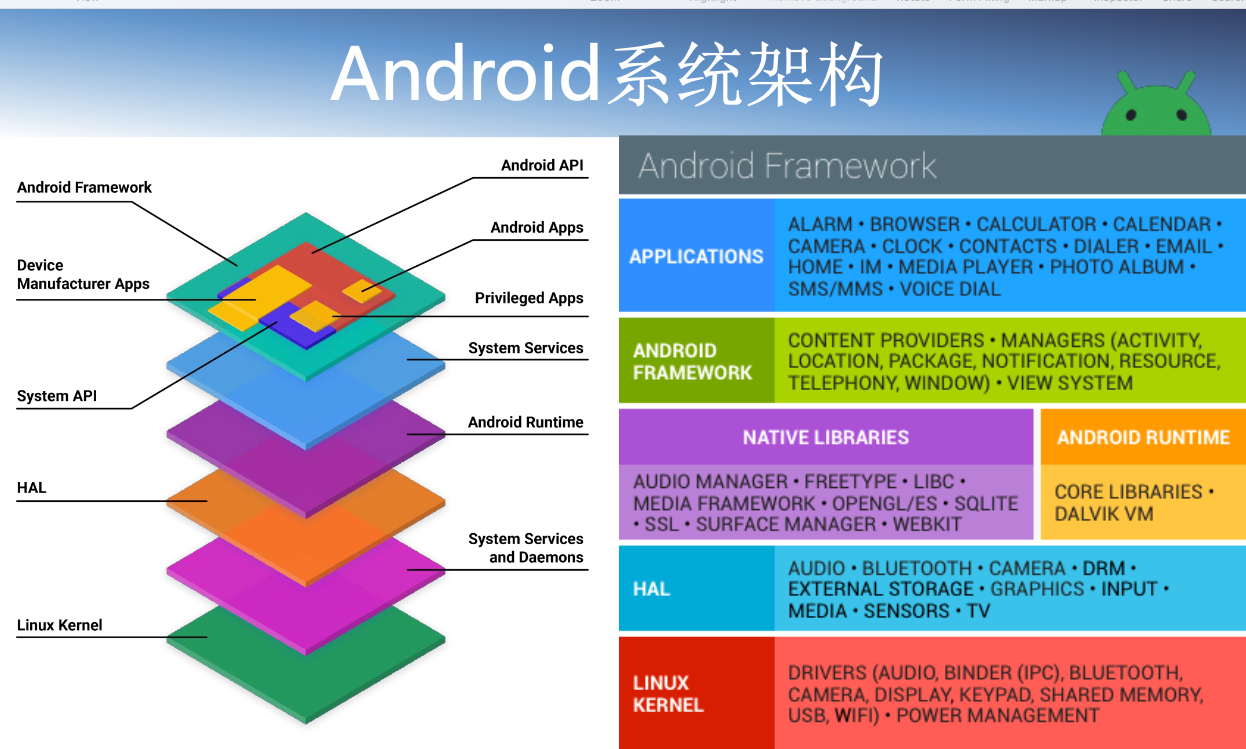
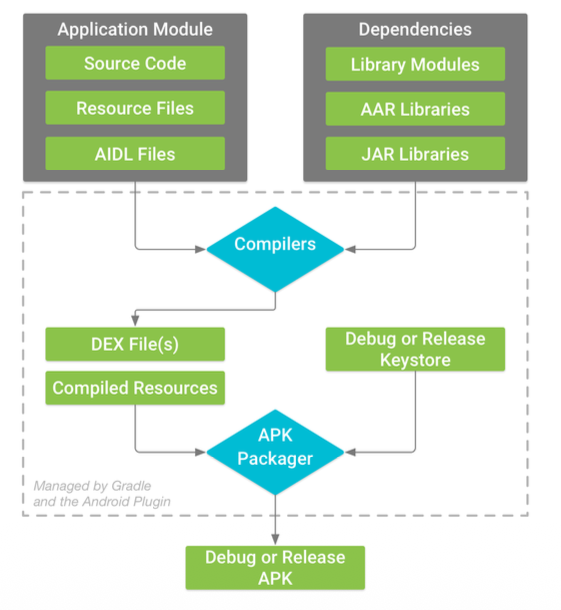
安卓构建流程
启动流程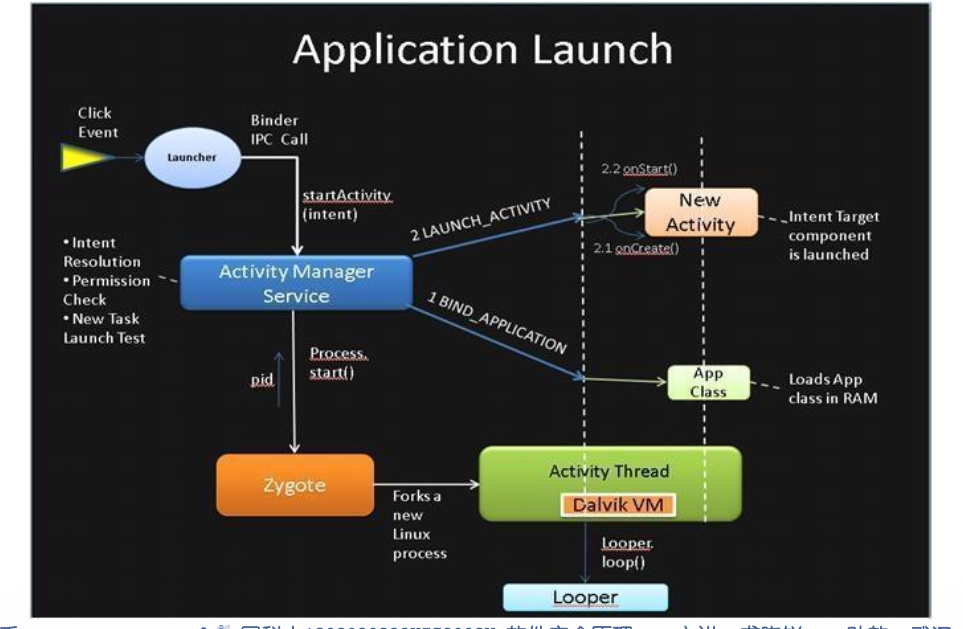
安卓逆向
- 一定包含加密后的Manifest文件
- 一定包含classes.dex文件
- 如果项目中使用了so库,一般在lib文件夹下
- 资源文件中加密的xml,可能在r或res文件夹下
- 使用了加壳措施的apk由于加壳方案不同,资源文件和dex文件的处理会有差异
apktool
app安全问题产生的原因:
- 开发门槛低导致的安全问题
- 第三方库导致的安全问题
- 应用重打包导致的安全问题
- 第三方市场监管不力导致的安全问题
iOS平台App安全
iOS是苹果公司为移动设备所开发的专有移动操作系统,属于类Unix系统,支持的设备包括iPhone、iPod touch和iPad。与Android不同的是iOS不支持任何非苹果公司的硬件设备。
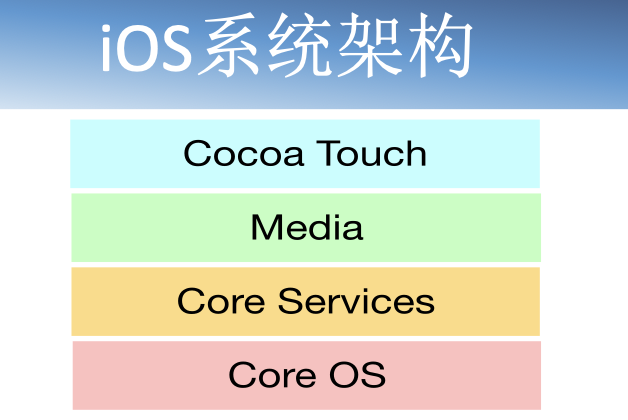
iOS系统分为可分为四级结构,由上至下分别为可触摸层(Cocoa Touch Layer)、媒体层(Media Layer)、核心服务层(Core Services Layer)、核心系统层(Core OS Layer),每个层级提供不同的服务。低层级结构提供基础服务如文件系统、内存管理、I/O操作等。高层级结构建立在低层级结构之上提供具体服务如UI控件、文件访问等。
开发语言:Objective-C、Swift
开发工具:Xcode
Objective C采用Clang作为前端,而Swift则采用swift()作为前端,二者LLVM(Low level vritual machine)作为编译器后端。
iOS逆向
– iTunesArtwork:app的高分辨率图标,通常是一个JPG图像文件
– iTunesMetadata:app的属性列表文件,是个二进制的plist文件
– META-INF(文件夹):作者猜测主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件纪录等功能
– Payload:里面有个.app的文件,右键显示包内容。
iOS App攻击面:用户本地攻击面、用户远程攻击面、内核攻击面
第十章 智能软件系统脆弱性
智能软件系统
计算机视觉、语音识别、自然语言理解、多媒体技术、信息检索与推荐
脆弱性与对抗样本攻击
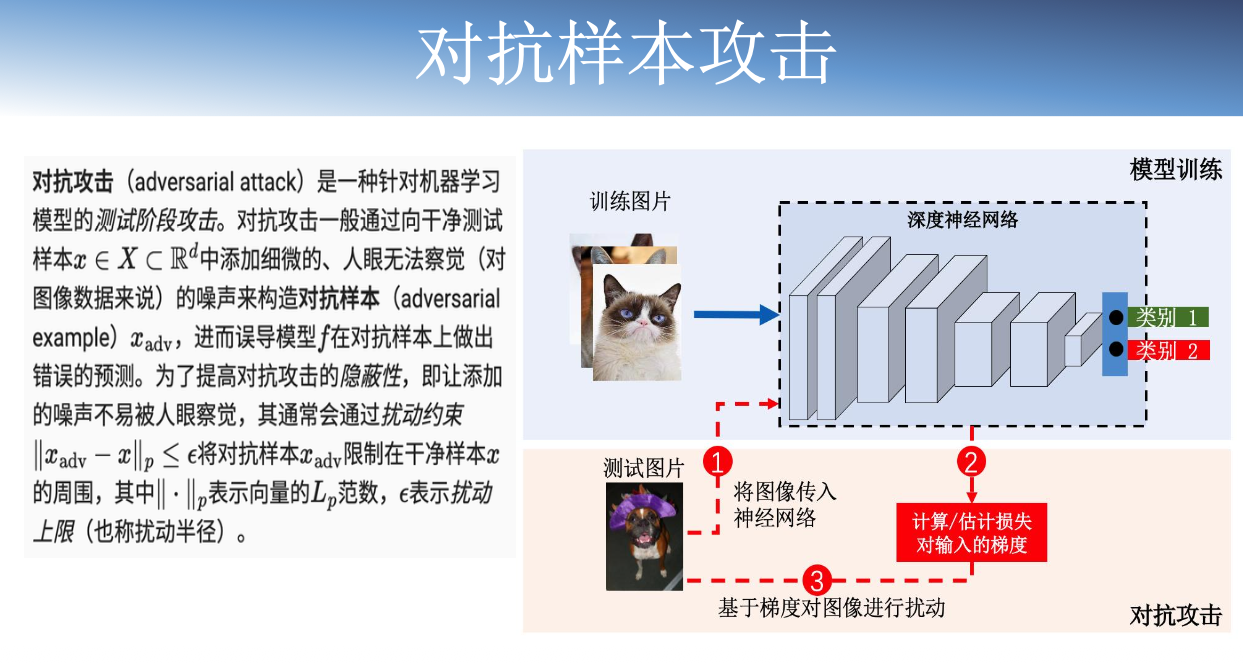
非目标攻击:对抗样本能够使模型输出错误预测结果。
目标攻击:对抗样本能够使模型输出指定错误结果。
数字攻击:对抗样本直接输入模型实现攻击。
物理攻击:不直接接触模型,通过相机、麦克风等传感器传递对抗干扰信息攻击模型。
这里介绍了各种各样的攻击方式。
对抗样本防御
- 对抗样本成因分析
– “知己知彼,百战不殆”
– 深入了解对抗样本的成因,设计防御方法从源头上消除攻击
- 对抗样本检测
– 让防御者对检测出来的攻击进行拒绝服务
– 通过检测到的查询样本定位到攻击者
- 对抗训练
– 当前主流的对抗防御手段
– 通过鲁棒优化的思想在训练过程中提高模型自身的鲁棒性漏洞模式(c语言)
提示注入攻击
提示注入攻击(PromptInjection)指的是攻击者通过精心构造的输入,诱导大语言模型(LLM)忽略开发者设定的原始指令和安全护栏,转而执行恶意操作。其根本原因是LLM在统一处理用户输入和系统指令时,难以严格区分“可信指令”与“不可信数据”。
防御:输入层防护、架构与处理层加固、输出层与运行时监控
模型幻觉
模型自信地生成不真实答案的情况
产生幻觉的根源:技术本质、训练数据的局限性、评估体系
第十一章 智能软件系统后门
后门攻击
后门模型在干净测试样本上具有正常的准确率。当且仅当测试样本中包含预先设定的后门触发器时,后门模型才会产生由攻击者预先指定的预测结果
通用型和专一型
定向型和非定向型
植入后门的方法:污染训练数据集、修改预训练模型
输入空间攻击
模型空间攻击
特征空间攻击
迁移学习攻击
联邦学习攻击
物理世界攻击
后门防御
数据集预处理
在线后门防御
离线后门防御
后门检测
后门检测是指对于一个给定的模型,在对trigger,攻击目标等都一无所知的情况下,判断该模型是否带有后门。
第十二章 软件开发与安全
软件安全问题的根源:复杂性、复用性、劣币效应
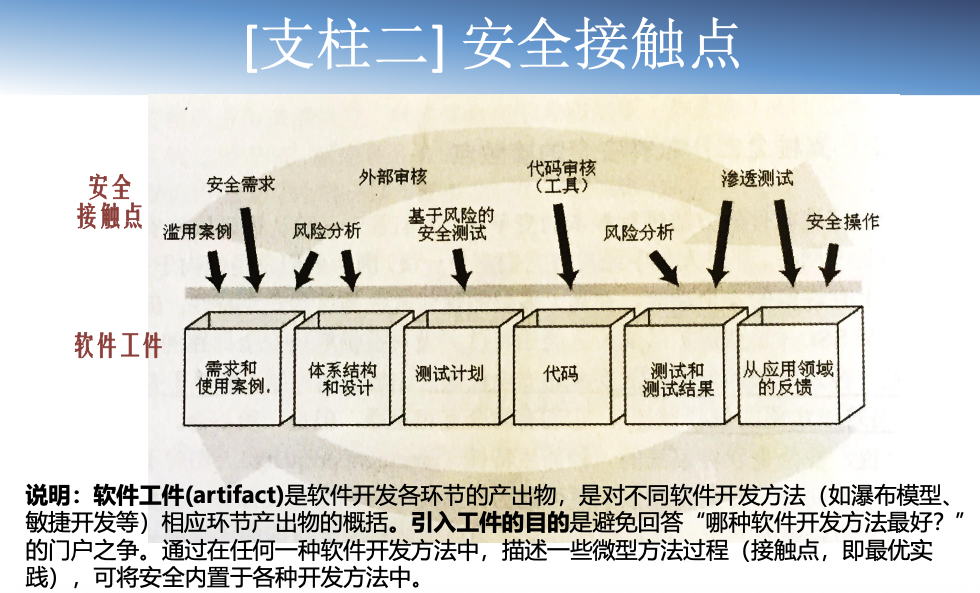
内构安全
内构安全 是一种协同化努力,通过提供实践、工具、指南、规则、原则及其它资源,让软件开发者、架构师和安全参与人员可以籍此在软件开发的每个阶段将安全构建到软件中去。
安全的软件开发三大支柱:风险管理、安全接触点、安全知识。
风险管理
安全风险是攻击者利用系统漏洞或人员漏洞影响系统正常功效的概率及其后果
安全风险 = 概率 × 影响
安全是一种风险管理
第十三章 软件安全开发方法
传统行业 vs. 互联网行业
微软SDL
软件产业SDL的挑战
华为SDL软件安全工程
DevSecOps
DevSecOps 是“开发、安全和运维”的缩写。它是一种文化取向、自动化方法和平台设计方法的汇集,将安全性作为整个 IT 生命周期的共同责任。
敏捷开发和 DevOps 广泛应用的同时,安全需求不断增长,DevSecOps在此基础上应运而生。
第十四章 软件供应链安全
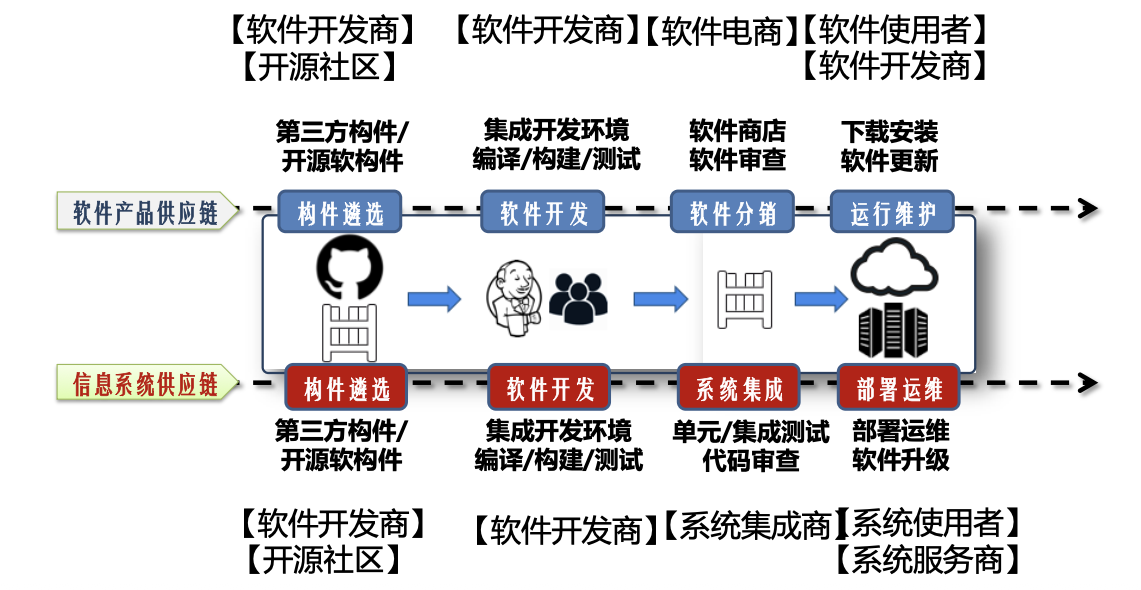
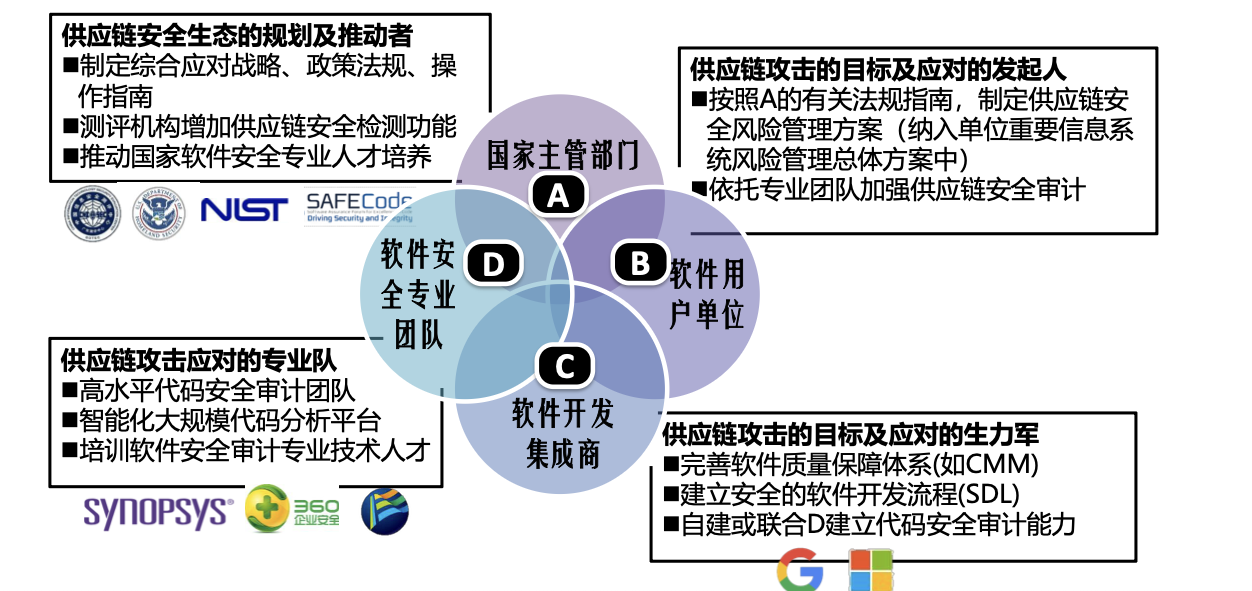
软件供应链安全生态体系:国家主管部分,软件用户单位,软件开发集成商、软件安全专业团队
常见漏洞模式
课件中提及的漏洞类型
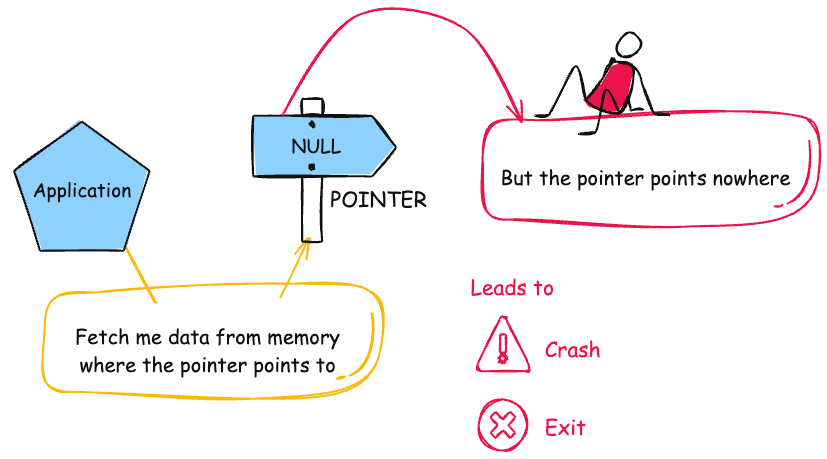
CWE-476 NULL Pointer Dereference(空指针解引用)
① 典型代码模式
struct obj *o = get_obj();
o->field = 1; // o 可能为 NULL或错误路径未返回:
p = malloc(sizeof(*p));
if (!p)
log_error(); // 未 return
p->x = 10;② 根因
- 指针来源不可信
- 错误路径与正常路径未隔离
- “假设不会失败”的编程习惯
③ 修改方案(直接可用)
❌ Before
p = malloc(sizeof(*p));
p->x = 1;✅ After(Fail-fast)
p = malloc(sizeof(*p));
if (!p)
return -ENOMEM;
p->x = 1;✅ 防御式写法(推荐)
if (unlikely(!p))
return -EINVAL;④ 审计检查点
- 所有
->/*p是否100% 可达非 NULL - 错误路径是否立即返回
- 是否存在 “log 但继续执行”
void host_lookup(char *user_supplied_addr){
struct hostent *hp;
in_addr_t *addr;
char hostname[64];
in_addr_t inet_addr(const char *cp);
/*routine that ensures user_supplied_addr is in the right format for conversion */
validate_addr_form(user_supplied_addr);
addr = inet_addr(user_supplied_addr);
hp = gethostbyaddr( addr, sizeof(struct in_addr), AF_INET);
strcpy(hostname, hp->h_name);
}没有检查gethostbyaddr函数的返回值。可能会返回一个空指针。
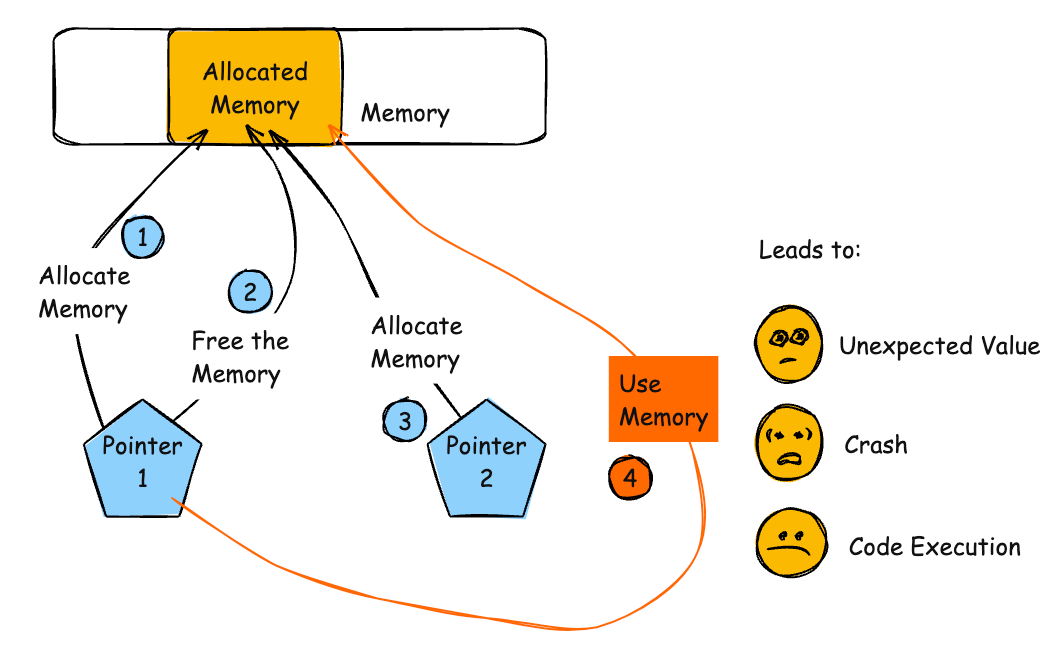
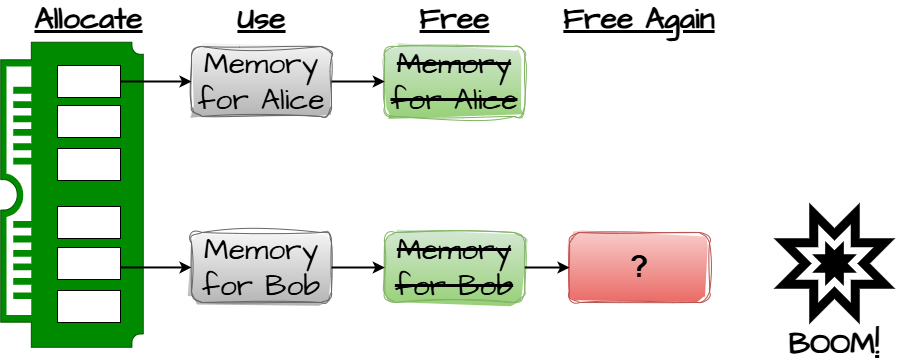
CWE-416 Use After Free(释放后重用)
① 典型代码模式
buf = malloc(128);
free(buf);
process(buf); // UAF更隐蔽版本(结构体成员):
free(obj->data);
obj->len = 0;
memcpy(obj->data, src, n); // UAF② 根因
- 生命周期不清晰
- 释放 ≠ 不可再访问
- 多模块共享指针
③ 修改方案
❌ Before
free(p);
use(p);✅ After(最基本)
free(p);
p = NULL;✅ 更优(所有权模型)
void destroy_obj(struct obj **o)
{
if (*o) {
free((*o)->data);
free(*o);
*o = NULL;
}
}④ 审计检查点
free()后是否仍可到达使用点- 指针是否被复制(alias)
- refcount 是否匹配
char* ptr = (char*)malloc (SIZE);
if (err) {
abrt = 1;
free(ptr);
}
...
if (abrt) {
logError("operation aborted before commit", ptr);
}CWE-415 Double Free(双重释放)
① 典型代码模式
if (err)
free(p);
...
free(p);或错误路径:
if (init_a())
goto err;
if (init_b())
goto err;
err:
free(p);② 根因
- 错误路径未区分已释放状态
- 缺乏资源状态机
③ 修改方案
❌ Before
free(p);
free(p);✅ After(状态保护)
if (p) {
free(p);
p = NULL;
}✅ 更推荐(集中释放)
err:
cleanup:
free(p);
return ret;④ 审计检查点
- 是否存在 多条路径调用 free
goto err是否安全- free 是否集中
CWE-843 Type Confusion(类型混淆)
① 典型代码模式
void *obj = get_object();
struct B *b = (struct B *)obj;
b->fn(); // 实际是 struct A或 union 误用:
union U {
int i;
char *p;
} u;
u.i = 1;
free(u.p); // 类型混淆② 根因
- 缺乏运行时类型信息
- 盲目使用
void * - 未验证对象来源
③ 修改方案
❌ Before
struct B *b = (struct B *)obj;✅ After(类型标签)
struct base {
int type;
};
if (obj->type != TYPE_B)
return -EINVAL;✅ C++ 方案
B *b = dynamic_cast<B*>(obj);
if (!b) return;④ 审计检查点
void *→ 强转是否安全- 是否存在 type field / magic
- 是否基于外部输入决定类型
#define NAME_TYPE 1
#define ID_TYPE 2
struct MessageBuffer
{
int msgType;
union {
char *name;
int nameID;
};
};
int main (int argc, char **argv) {
struct MessageBuffer buf;
char *defaultMessage = "Hello World";
buf.msgType = NAME_TYPE;
buf.name = defaultMessage;
printf("Pointer of buf.name is %p\n", buf.name);
/* This particular value for nameID is used to make the code architecture-independent. If coming from untrusted input, it could be any value. */
buf.nameID = (int)(defaultMessage + 1);
printf("Pointer of buf.name is now %p\n", buf.name);
if (buf.msgType == NAME_TYPE) {
printf("Message: %s\n", buf.name);
}
else {
printf("Message: Use ID %d\n", buf.nameID);
}
}CWE-704 Incorrect Type Conversion or Cast(不正确的类型转换)
① 典型代码模式
int len = recv_len();
size_t size = len; // len < 0
malloc(size);② 根因
- 隐式符号扩展
- 忽略类型边界
③ 修改方案
❌ Before
size_t size = len;✅ After
if (len < 0)
return -EINVAL;
size_t size = (size_t)len;④ 审计检查点
- signed → unsigned
- size_t ← int
- 隐式转换
unsigned int readdata () {
int amount = 0;
...
amount = accessmainframe();
...
return amount;
}If the return value of accessmainframe() is -1, then the return value of readdata() will be 4,294,967,295 on a system that uses 32-bit integers.
CWE-911 Improper Update of Reference Count(引用计数更新不当)
① 典型代码模式
obj->refcnt--;
if (obj->refcnt == 0)
free(obj);② 根因
- 非原子操作
- refcnt 不对称
③ 修改方案
❌ Before
obj->refcnt++;✅ After(原子)
atomic_fetch_add(&obj->refcnt, 1);✅ Linux 风格
refcount_inc(&obj->refcnt);④ 审计检查点
- inc / dec 是否配对
- 是否存在并发
- 是否可能溢出
CWE-366 Race Condition within a Thread(线程内竞态)
① 典型代码模式
if (obj->valid)
use(obj);中间可能被信号处理修改。
③ 修改方案
❌ Before
if (flag)
do_x();✅ After
bool f = flag;
if (f)
do_x();④ 审计检查点
- 检查与使用是否分离
- 回调 / signal 是否可重入
int foo = 0;
int storenum(int num) {
static int counter = 0;
counter++;
if (num > foo) foo = num;
return foo;
}全局变量foo的问题
CWE-367 TOCTOU(条件竞争)
① 典型代码模式
if (access(path, W_OK) == 0)
fd = open(path, O_WRONLY);③ 修改方案
❌ Before
access();
open();✅ After
fd = open(path, O_WRONLY | O_CREAT | O_EXCL, 0600);或:
fd = open(path, O_WRONLY);
fstat(fd, &st);④ 审计检查点
- access + open
- stat + open
- 路径型检查
struct stat *sb;
...
lstat("...",sb); // it has not been updated since the last time it was read
printf("stated file\n");
if (sb->st_mtimespec==...){
print("Now updating things\n");
updateThings();文件可能会在printf的时候更新。
CWE-125 Out-of-bounds Read(越界读)
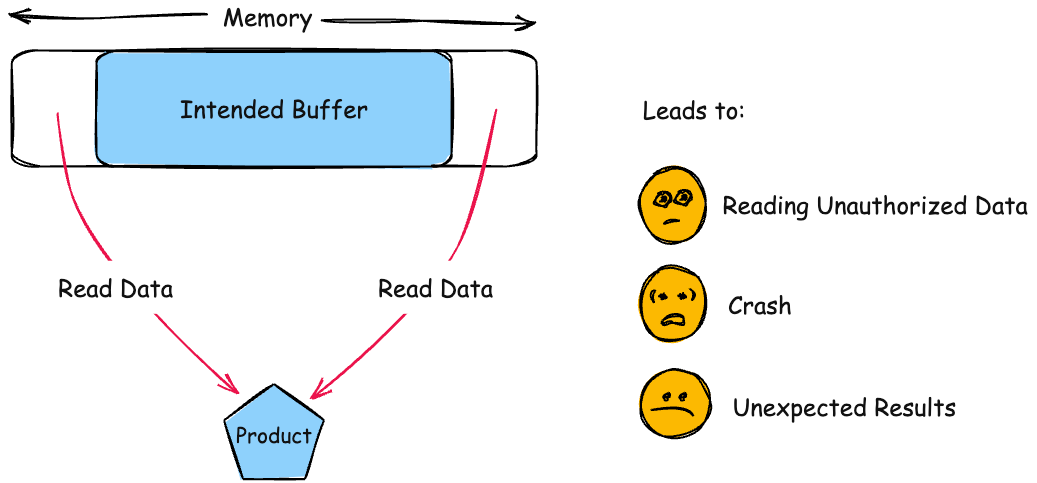
① 典型代码模式
char buf[8];
read(fd, buf, len); // len > 8③ 修改方案
if (len > sizeof(buf))
return -EINVAL;int getValueFromArray(int *array, int len, int index) {
int value;
// check that the array index is less than the maximum
// length of the array
if (index < len) {
// get the value at the specified index of the array
value = array[index];
}
// if array index is invalid then output error message
// and return value indicating error
else {
printf("Value is: %d\n", array[index]);
value = -1;
}
return value;
}CWE-787 Out-of-bounds Write(越界写)
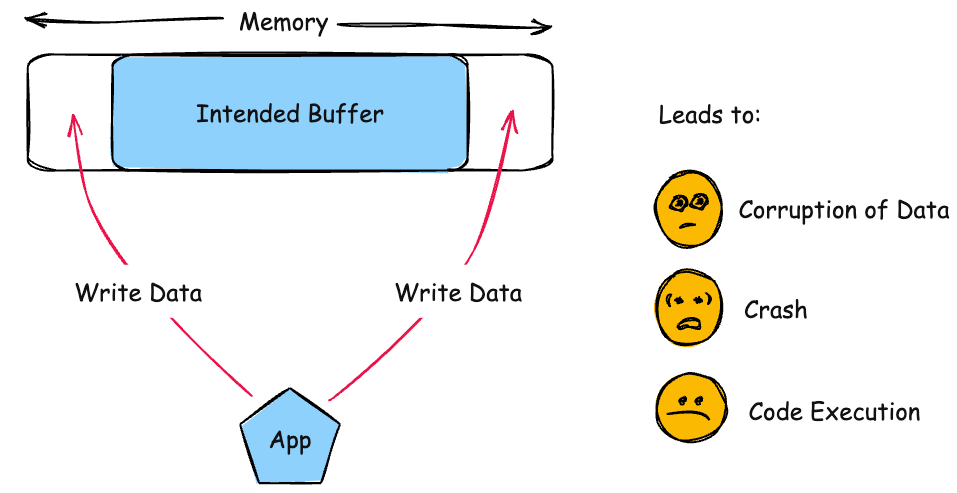
① 典型代码模式
memcpy(buf, src, len);③ 修改方案
memcpy(buf, src, min(len, sizeof(buf)));或:
snprintf(buf, sizeof(buf), "%s", src);int id_sequence[3];
/* Populate the id array. */
id_sequence[0] = 123;
id_sequence[1] = 234;
id_sequence[2] = 345;
id_sequence[3] = 456;int returnChunkSize(void *) {
/* if chunk info is valid, return the size of usable memory,
* else, return -1 to indicate an error
*/
...
}
int main() {
...
memcpy(destBuf, srcBuf, (returnChunkSize(destBuf)-1));
...
}memcpy的最后一个参数是unsigned
CWE-190 Integer Overflow or Wraparound(整数溢出)
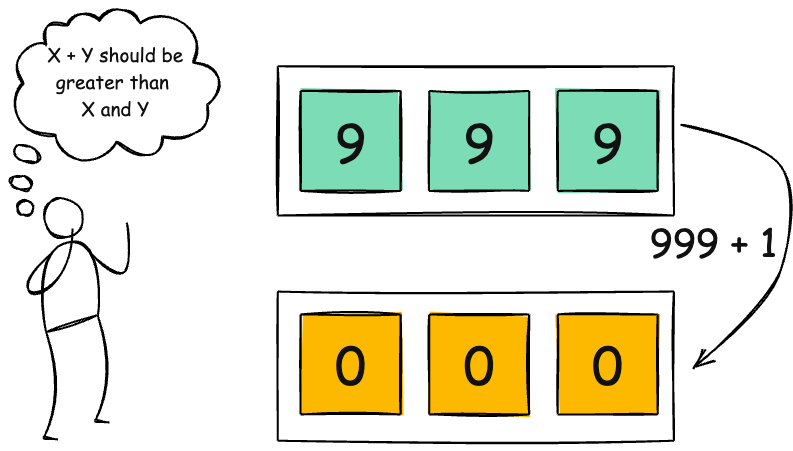
① 典型代码模式
int total = count * size;
malloc(total);③ 修改方案(官方推荐)
if (count > INT_MAX / size)
return -EINVAL;或:
if (__builtin_mul_overflow(count, size, &total))
return -EINVAL;img_t table_ptr; /*struct containing img data, 10kB each*/
int num_imgs;
...
num_imgs = get_num_imgs();
table_ptr = (img_t*)malloc(sizeof(img_t)*num_imgs);
...CWE-193: Off-by-one Error
#define PATH_SIZE 60
char filename[PATH_SIZE];
for(i=0; i<=PATH_SIZE; i++) {
char c = fgetc(stdin);
if (c == EOF) {
filename[i] = '\0';
}
else {
filename[i] = c;
}
}char firstname[20];
char lastname[20];
char fullname[40];
fullname[0] = '\0';
strncat(fullname, firstname, 20);
strncat(fullname, lastname, 20);在此示例中,代码未考虑终止空字符,导致写入缓冲区末尾之外的一个字节。
首次调用 strncat() 向 fullname[] 追加最多 20 个字符及一个终止空字符。此时分配的空间充足,首次调用不存在漏洞。但第二次调用 strncat() 可能再次追加 20 个字符。该代码未考虑strncat()自动添加的终止空字符。该空字符将被写入fullname[]缓冲区末尾之后的第1个字节位置。因此第二次strncat()调用存在偏移量错误,其第三个参数应为19。
使用strncat()这类函数时,必须在缓冲区末尾预留一个字节用于终止空字符,从而规避偏移量错误。此外,strncat()的最后一个参数表示要追加的字符数,该值必须小于缓冲区剩余空间。请注意不要直接使用缓冲区的总大小。
char firstname[20];
char lastname[20];
char fullname[40];
fullname[0] = '\0';
strncat(fullname, firstname, sizeof(fullname)-strlen(fullname)-1);
strncat(fullname, lastname, sizeof(fullname)-strlen(fullname)-1);