

自然语言处理基础期末复习
授课教师:胡玥、曹亚男、方芳
考试信息:题目更难、覆盖更广、大模型更多了。主观题只需要核心理念(不需要完整公式)。
前面的是填空和简答题。后面三个方面是主观题。(曹老师说这些点有95分)复习的时候就以下面这些为重点来学习,然后对一些关键性的概念也会在文中提及。

绪论
自然语言处理(Natural Language Processing,简称NLP)是利用计算机为工具,对人类特有的书面形式和口头形式的自然语言的信息进行各种类型处理和加工的技术。
自然语言处理是人工智能的一个分支,用于分析、理解和生成自然语言,以方便人和计算机设备以及人与人之间的交流
NLP核心任务:信息抽取、文本分类、情感分析、问答系统、机器阅读理解、智能对话、自动文摘、机器翻译
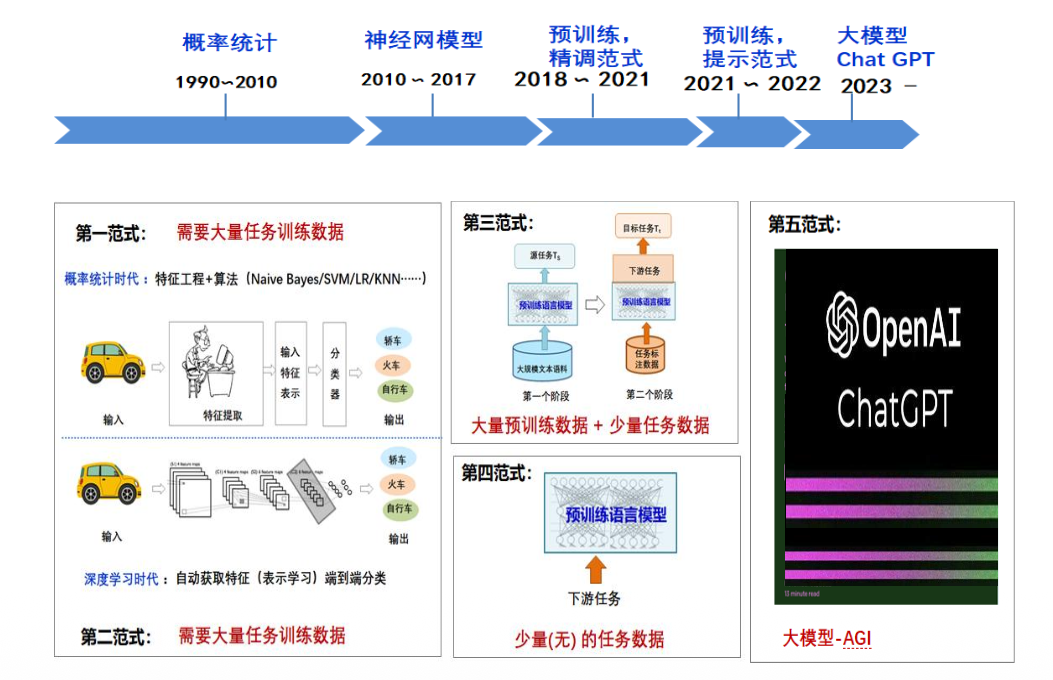
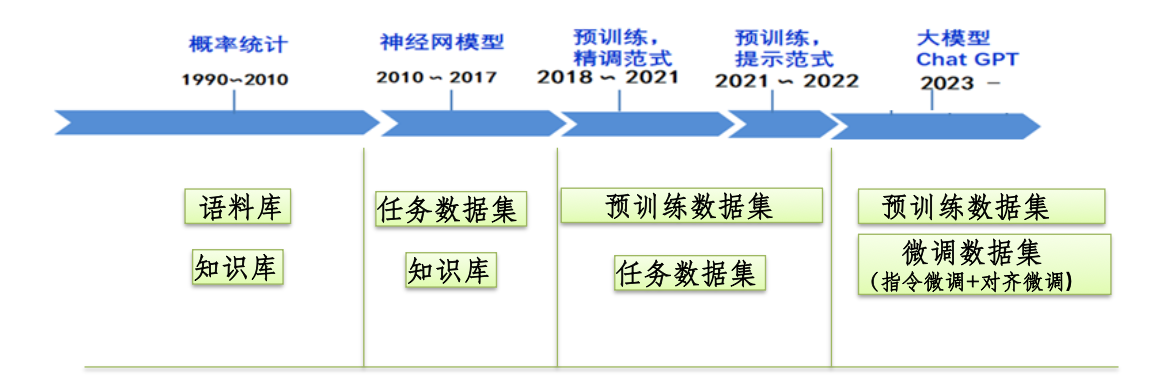
NLP任务的机器学习方法经历了五次范式变迁——考点1

P1.非神经网络时代的完全监督学习–特征工程(Fully Supervised Learning, Non-Neural Network)
模型:概率模型,如贝叶斯,隐马尔可夫,最大熵,条件随机场等
特点:人工进行大量的特征模版定义,一般采用流水线解决方案
优点:可解释性强
缺点:解决问题方法复杂
对比深度学习方法:深度学习方法解决问题方法简单,但可解释性差
以机器翻译任务为例说明概率统计方法和深度学习/神经网络方法的区别
概率统计法机器翻译:树到树的翻译模型
- 句法分析:将源语言句子分析为一棵句法结构树(短语结构树)
- 树到树的转换:递归地将源语言句子的句法结构树转换为目标语言句子的句法结构树,拼接叶结点得到译文
特点:流水线处理过程,中间过程复杂,但解释性强。
深度学习法机器翻译:神经网络模型
特点:只需双语平行语料进行端到端训练,翻译过程不需词法分析/句法分析等中间过程,直接端到端翻译 。方法简单,但解释性差。
以情感分类说明后四种范式的区别
P2.基于神经网络的完全监督学习–架构工程(Fully Supervised Learning, Neural Network)
模型:各种神经网络模型(CNN,RNN, Transformer,GNN 等)
特点:模型自动提取特征,一般端到端解决方案
优点:处理问题的方法变得简单
缺点:需要大量标注数据(有监督),可解释性性差
情感分类
文本:这个餐厅的服务真不错 → 情感分类标签
方法:建模神经网将文本形成文本表示,然后进行分类
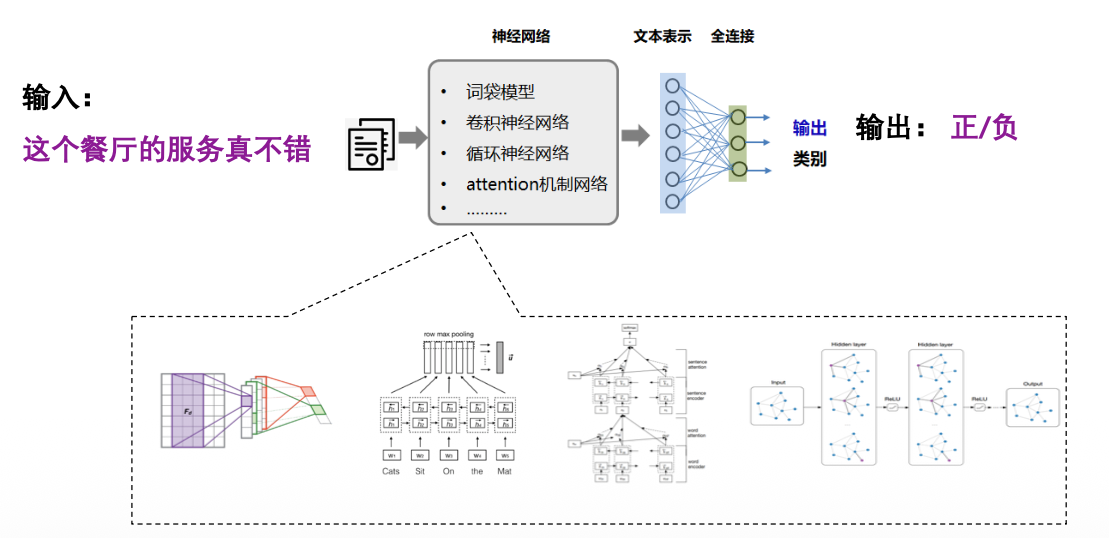
P3.预训练,精调范式 –目标工程 (Pre-train, Fine-tune)
特点:引入各种辅助任务loss,将其添加到预训练模型中,然后继续pre-training,以便让其适配下游任务,之后,通过引入额外的参数,用特定任务的目标函数对模型进行微调,使其更适配下游任务。研究重点转向了目标工程,设计在预训练和微调阶段使用的训练目标
基本思想:自然语言处理任务往往用有监督方法学习,但标注数据有限,预训练方法可以通过自监督学习从大规模数据中获得与具体任务无关的预训练模型 ,然后用训练好的预训练模型提高下游任务的性能。
数据特点:需要领域数据进行任务微调
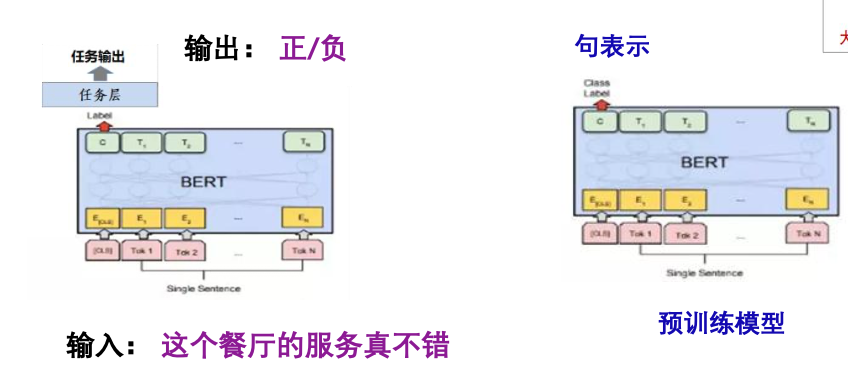
P4.预训练,提示,预测范式–prompt挖掘工程 (Pre-train, Prompt, Predict)
Prompt is the technique of making better use of the Knowledge from the pre-trained model by adding additional texts to the input
特点:不通过目标工程使预训练的语言模型(LM)适应下游任务,而是将下游任务建模的方式重新定义**(Reformulate),通过利用合适prompt实现不对预训练语言模型改动太多,尽量在原始LM**上解决任务的问题
核心思想:改变任务形式利用预训练模型完成任务(用于小样本学习或半监督学习,某些场景下甚至能做到零样本学习。)
数据特点: 少量(无)的任务数据
prompt learning激活了类似于小样本学习等场景
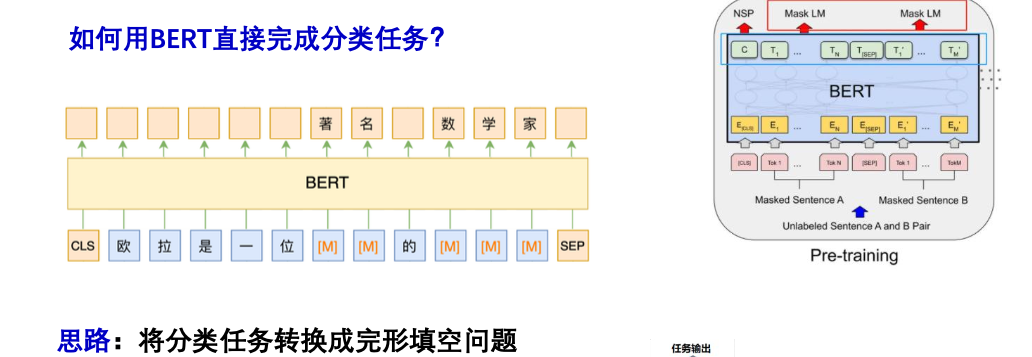
方法:给输入的文本增加一个前缀或者后缀描述,并且Mask掉某些Token,转换为完形填空问题,转换要尽可能与原来的句子组成一句自然的话
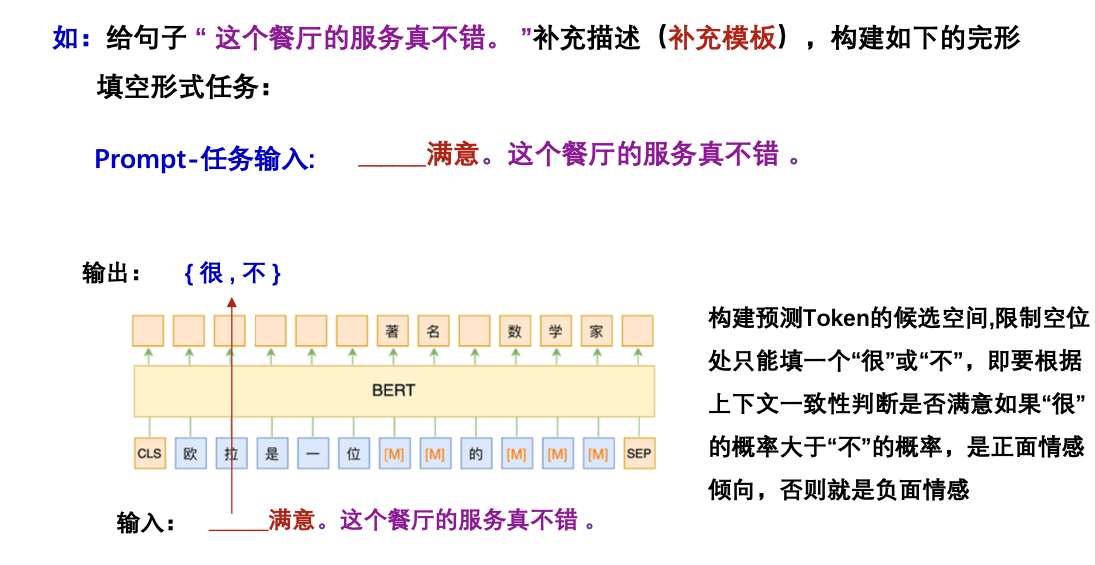
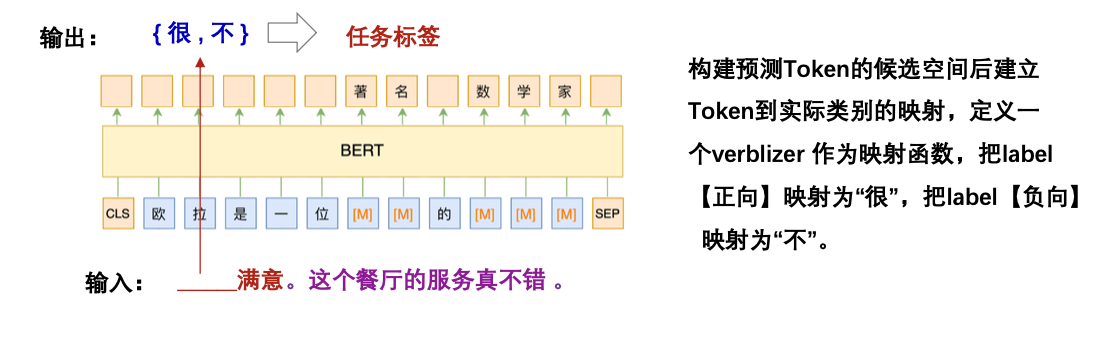
通过任务转换可以用MLM模型给出预测结果,而MLM模型的训练可以不需要监督数据,因此理论上这能够实现零样本学习。(如用少量任务样本微调一下模型,效果更好)
P5. 大模型LLM (Chat GPT)
特点:通用预训练语言模型(大模型),将下游任务统一为生成式任务,通过提示学习,上下文学习,思维链,检索增强等方式完成各类任务
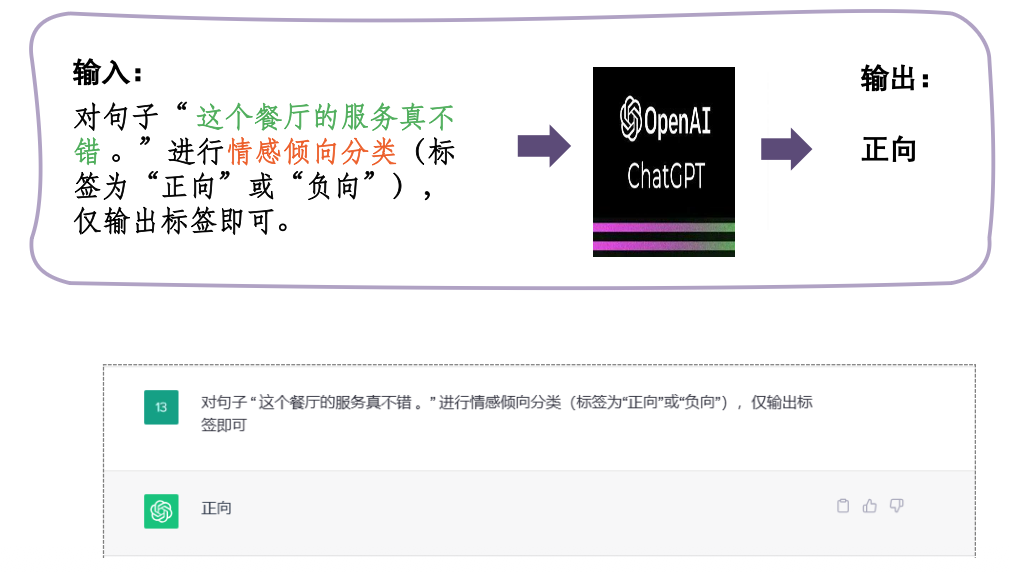
在大模型时代,依靠大模型强大的语言生成能力和理解能力,已经可以使用指令去激发模型的各种能力,进而用自然对话的方式来解决情感分析等基础任务了
五个范式的总结
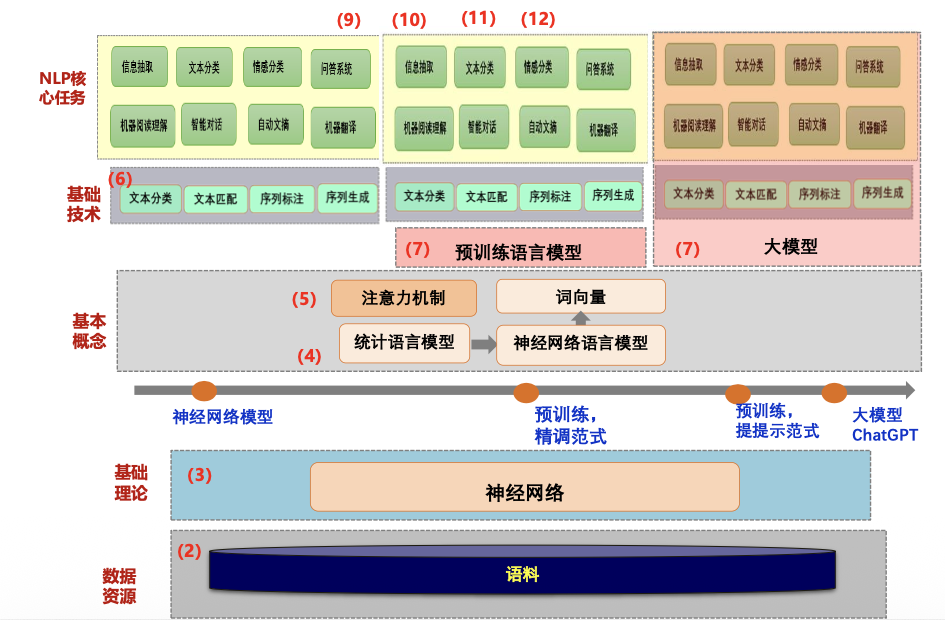
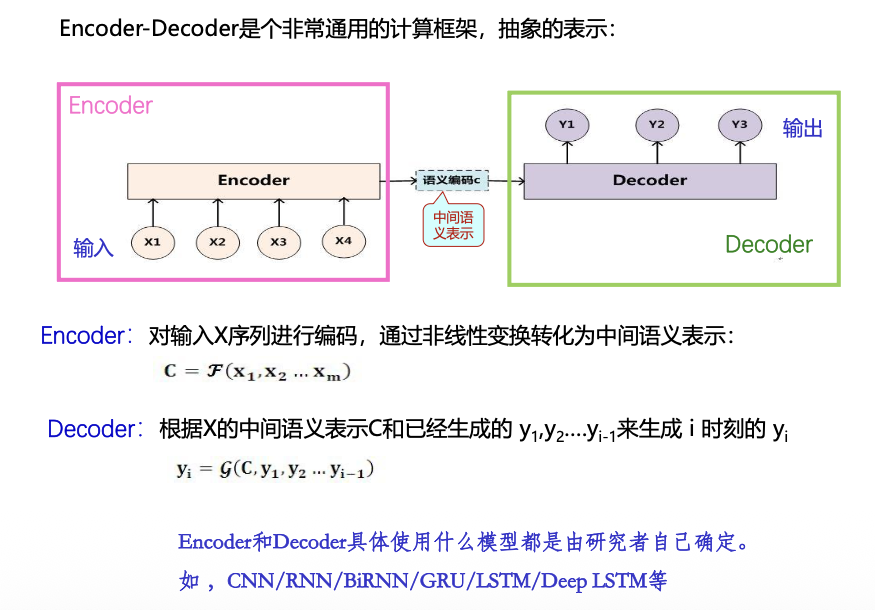
授课体系
第二章 数据资源
语料库:指存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的语料文本。
语言知识库:从大量的实例语料中提炼、抽象、概括出来的系统的语言知识,如电子词典、句法规则库、词法分析规则库等。
指令微调数据集: 该类数据集是有标注数据集,主要对大语言模型进行符合人类习惯输出的微调训练。一般有人工标注数据集和用模型合成方法生成的数据集
第三章 深度学习基础模型
基础知识——考点4
神经元模型
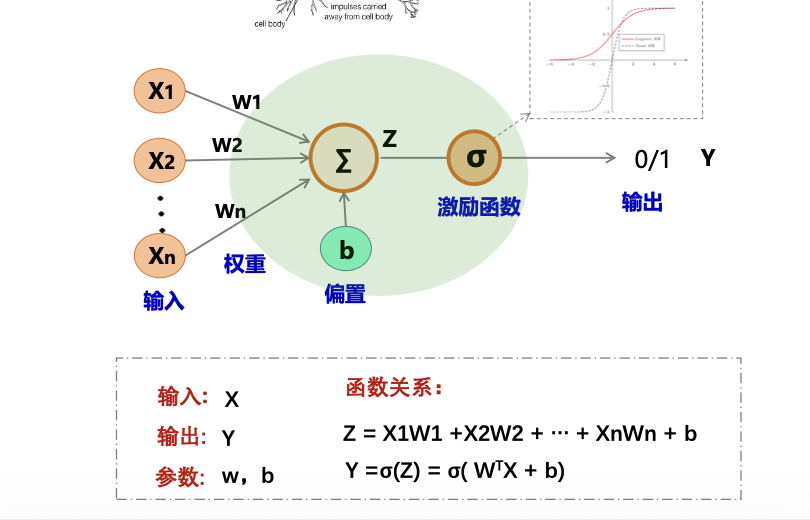
激活函数:Sigmoid/Logistic, tanh ,ReLU, ELU。
梯度下降法
迭代调参思想:通过调整参数,让模型输出递归性地逼近标准输出。
- 用误差定义损失函数L(θ)——定义目标函数
- 将问题转化为求极值问题求 minC(θ)——优化目标函数
损失函数:0-1损失,平方损失函数,绝对值损失函数,对数损失函数,交叉熵,Hinge损失,指数损失。

梯度下降中的问题:1.参数初值设置将影响参数学习效果避免各参数初值设为相同值,参数初值设置尽量随机。2.学习率 η 设置时要注意不能过大或过小
反向传播算法
如何求每一层的导数是一个问题
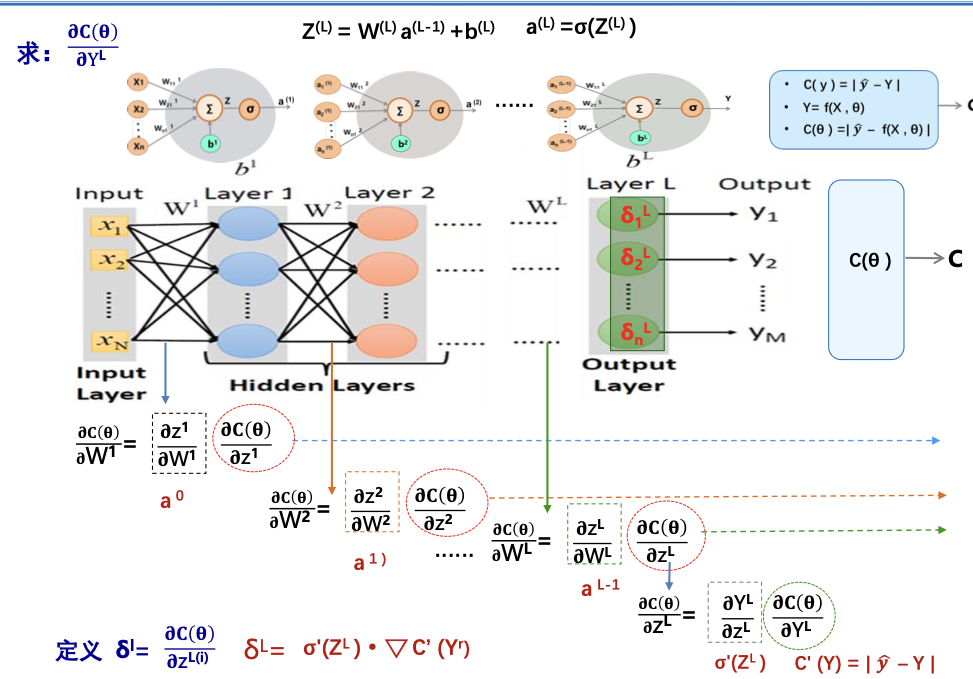
首先计算最后层误差δL ,然后根据误差反传公式求得倒数第二层误差δL-1直至第一层。
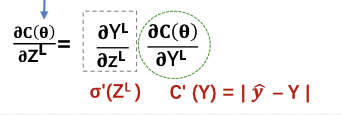

梯度消失问题
在神经网络中误差反向传播的迭代公式需要用到激活函数的导数误差从输出层反向传播时每层都要乘激活函数导数。这样当激活函数导数值小于 1 时 ,误差经过每一层传递都会不断衰减,当网络很深时甚至消失。
解决方法:选择合适的激活函数、用复杂的门结构代替激活函数、残差结构
梯度爆炸问题
梯度爆炸是指在反向传播过程中,梯度值随着层数的增加而迅速增大,最终变得非常大,超出了神经网络的正常处理范围,从而导致模型参数更新不稳定,甚至训练失败。
梯度爆炸的原因主要包括权重初始化过大、网络层数过多以及学习率设置过高等
缓解措施:使用梯度裁剪、合理初始化权重、调整学习率并选择稳定的优化算法来降低梯度爆炸的风险。
过拟合的定义
过拟合是指机器学习模型在训练数据上表现得非常好(例如,准确率极高),但在未见过的新数据(测试集或实际应用场景)上表现明显下降。这种现象的本质在于模型过度学习了训练数据中的噪声和特定样本特征,而不是学习到数据的普遍规律。
原因:模型复杂度过高、训练时间过长、数据量不足。
影响:过拟合会导致模型在新数据上的预测能力下降,无法准确分类或预测。这是机器学习模型的主要目标之一,即能够对未见过的数据进行有效的预测。
解决过拟合的方法:正则化、交叉验证、早停法、数据增强、简化模型。
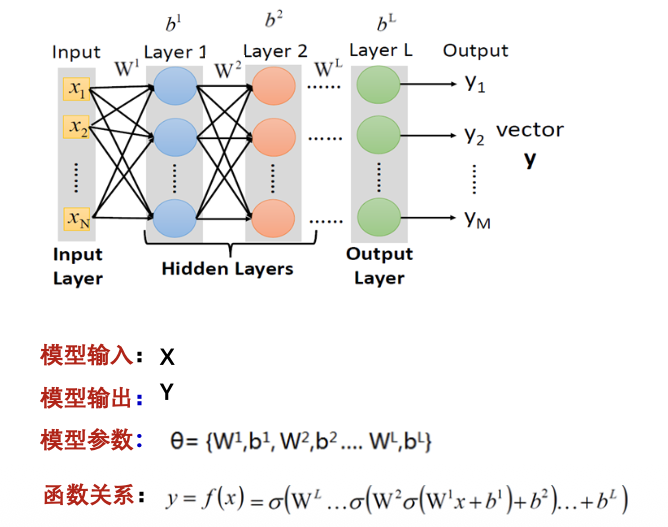
前馈神经网络DNN
卷积神经网络
图卷积神经网络
循环神经网络——考点3
核心概念:将处理问题在时序上分解为一系列相同的“单元”,单元的神经网络可以在时序上展开,且能将上一时刻的结果传递给下一时刻,整个网络按时间轴展开。即可变长。
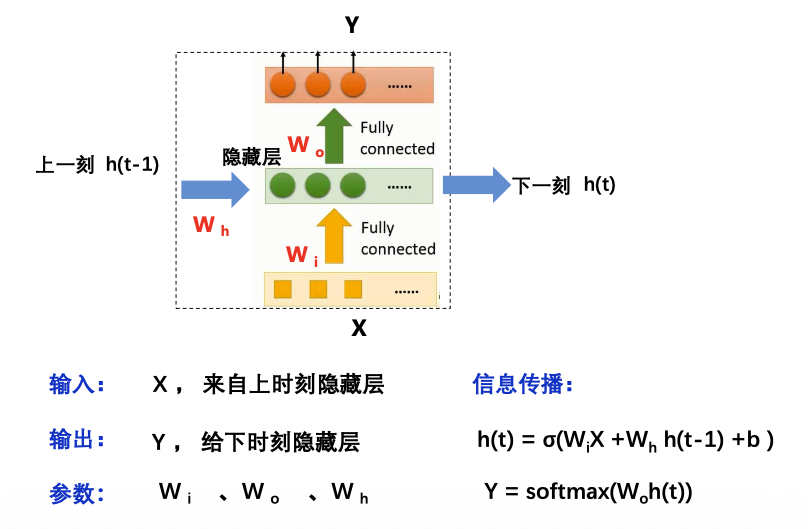
输入输出结构
参数学习算法:BPTT(这个算法优点复杂,可以仔细单独仔细研究一下)
基本原理是将RNN的计算图在时间上展开,以便计算每个时间步的梯度,从而更新网络的权重
循环神经网络改进及变形
问题:距当前节点越远的节点对当前节点处理影响越小,无法建模长时间的依赖(循环神经网络的长期依赖问题 )
长短时记忆神经网络:LSTM(long short-term memory)
LSTM 通过设计“门”结构实现保留信息和选择信息功能
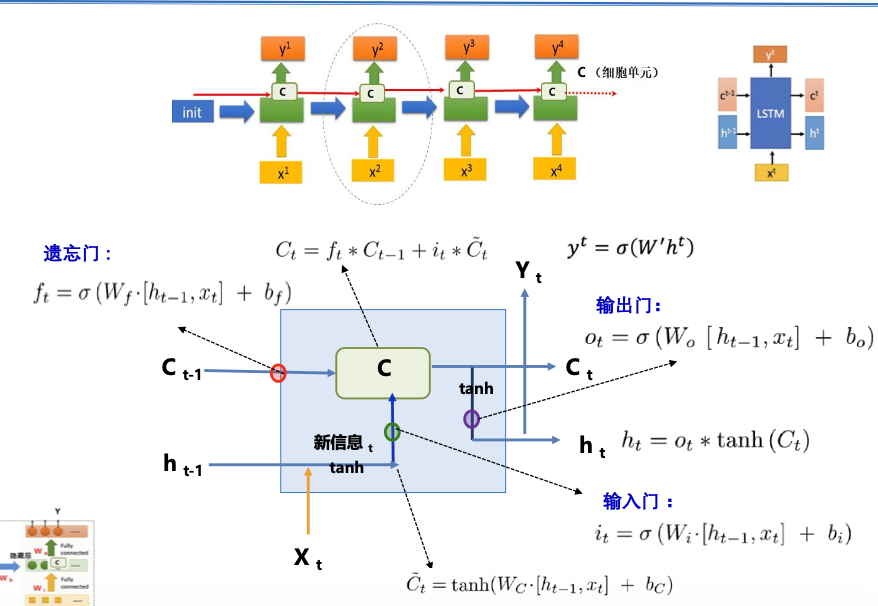
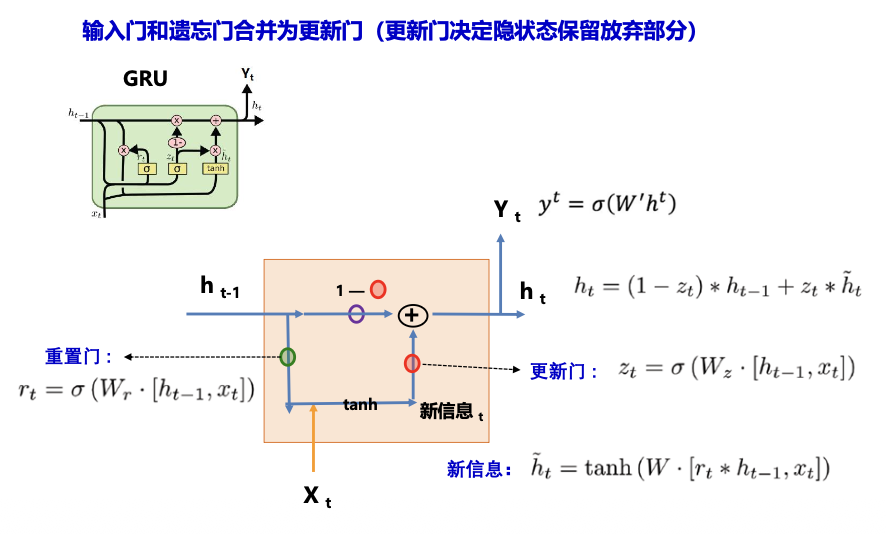
GRU (Gated Recurrent Unit)
LSTM 简化: 输入门和遗忘门合并为更新门(更新门决定隐状态保留放弃部分)
其他变形:DeepRNN、Bidirectional RNNs、 Deep Bidirectional RNN
第四章 语言模型+词向量
统计语言模型
语言模型基本思想:用句子S=w1,w2,…,wn 的概率 p(S) 刻画句子的合理性
n-gram 模型假设一个词的出现概率只与它前面的n-1个词相关
1元文法模型就是独立于历史
神经语言模型
使用DNN 学习模型参数 :NNLM 模型
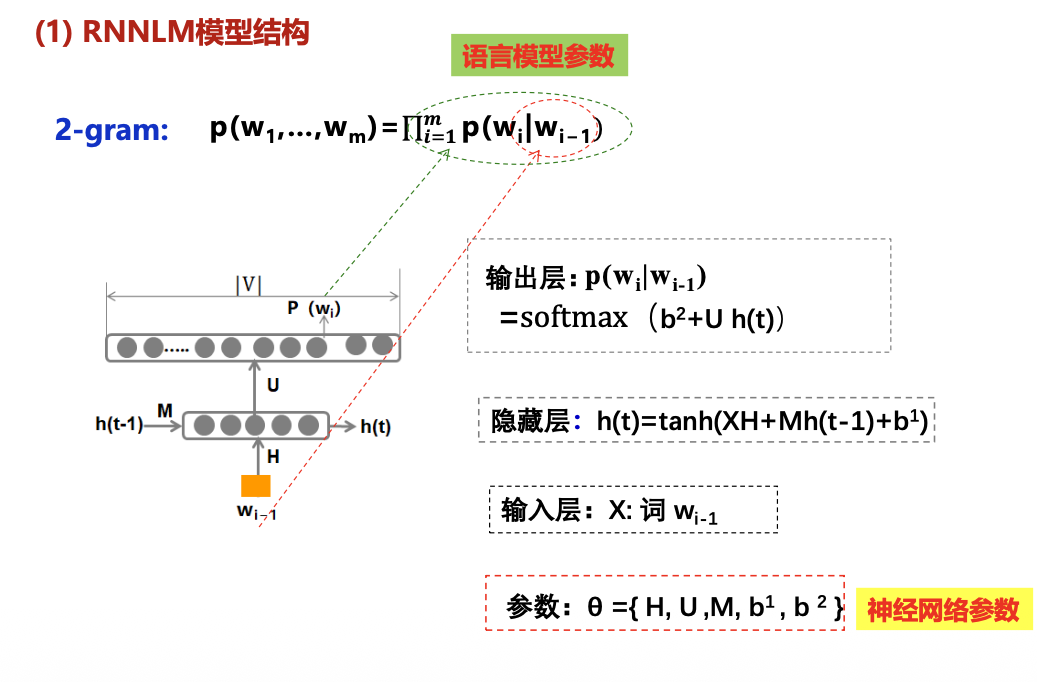
使用RNN 学习模型参数 : RNNLM 模型
NNLM
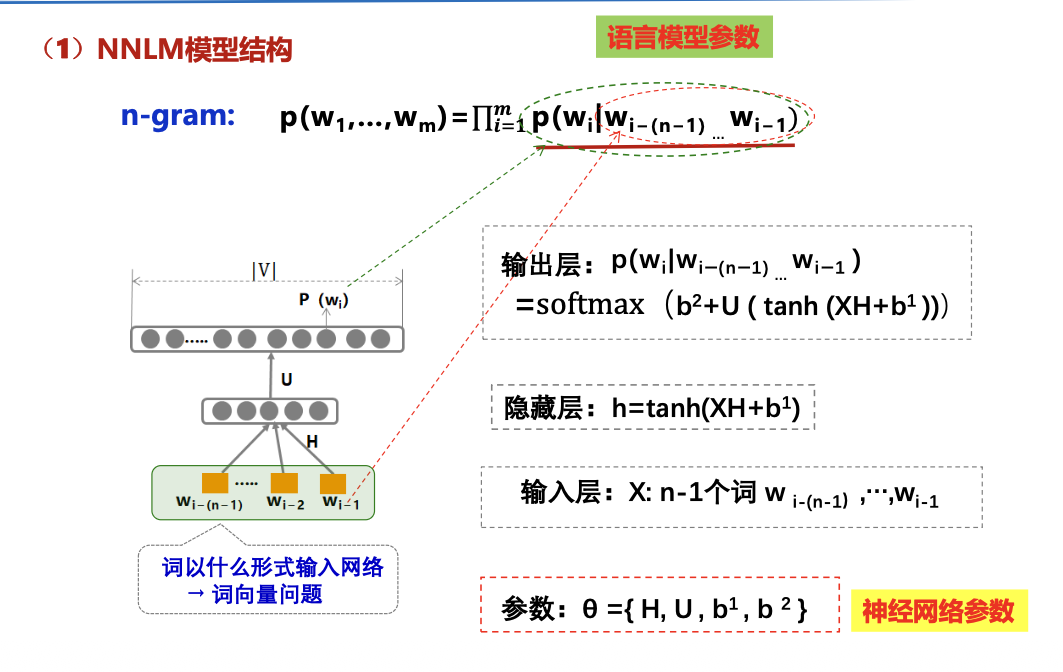
每求一个参数用一遍神经网络
RNNLM——考点3
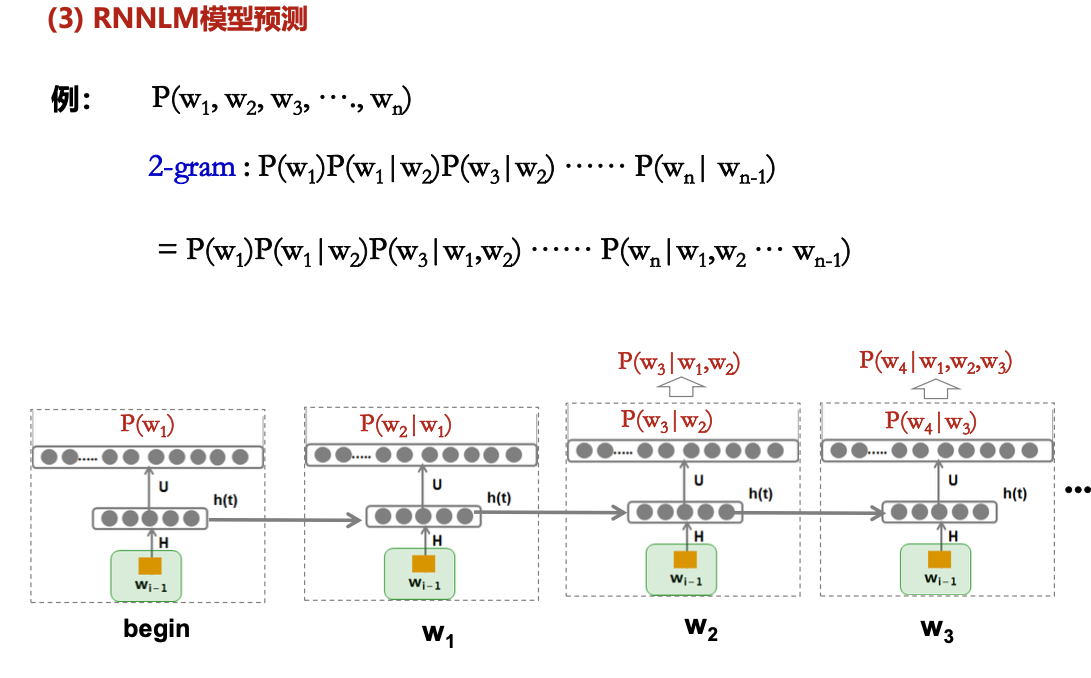
随着模型逐个读入语料中的词w1;w2 ….隐藏层不断地更新为h(1),h(2)….. ,通过这种迭代推进方式,每个隐藏层实际上包含了此前所有上文的信息,相比NNLM 只能采用上文n 元短语作为近似,RNNLM 包含了更丰富的上文信息,也有潜力达到更好的效果。
RNN语言模型变形
正向语言模型、反向语言模型、双向语言模型、单向多层RNN语言模型、双向多层RNN语言模型
词向量
one-hot
不计算词之间的共现频度,直接用“基于词的上下文词来预测当前词”或“基于当前词预测上下文词”的方法构造构造低维稠密向量作为词的分布式表示 。
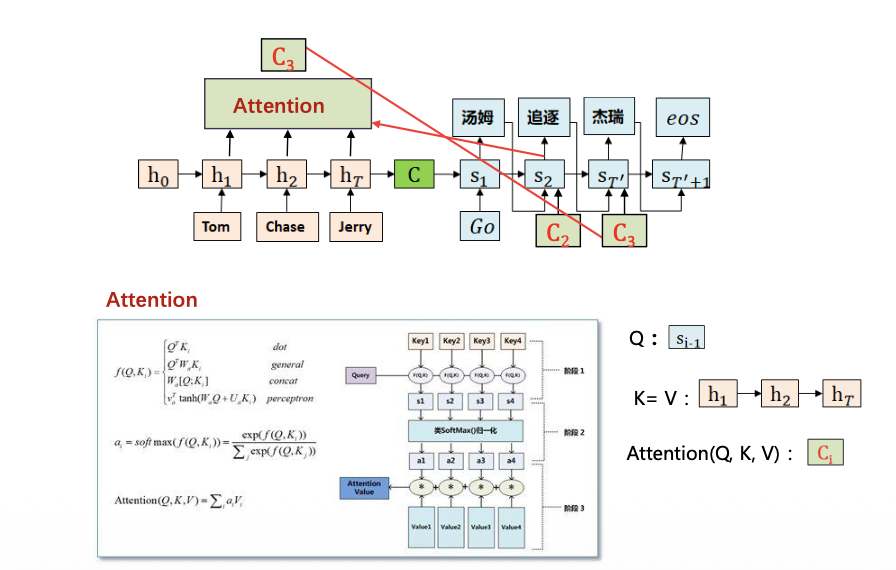
第五章 NLP中的注意力机制——考点3
概述
注意力机制:加权求和模块
作用:等权求和 → 加权求和(任意节点间建立关联关系)
传统注意力机制
加权求和模块(分为三个阶段)
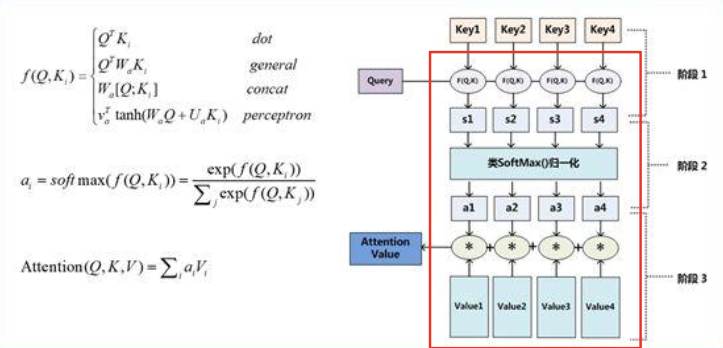
注意力模块训练:将模块放到整体模型中,不需要额外的训练数据权重可以由模块中的参数学到
注意力模块评价:放到各个任务中检验,通过任务指标的提升证明模块的效果
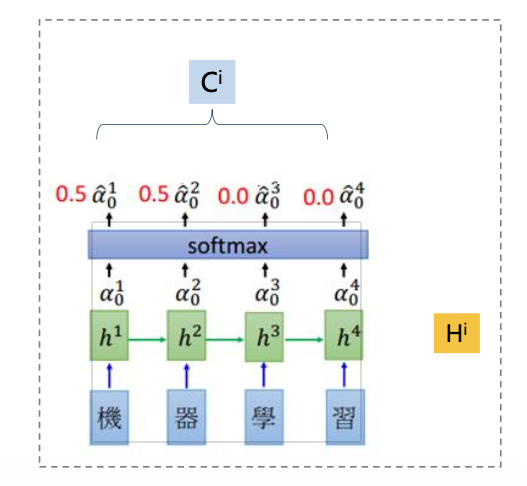
软注意力 Soft Attention
在求注意力分配概率分布的时候,对于输入句子X中任意一个单词都给出个概率,是个概率分布。
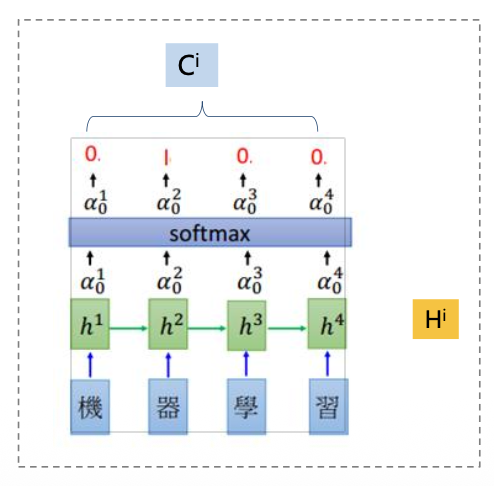
硬注意力 Hard Attention
直接从输入句子里面找到某个特定的单词,然后把目标句子单词和这个单词对齐,而其它输入句子中的单词硬性地认为对齐概率为0
全局注意力 Global Attention
Decode端Attention计算时要考虑输Ecoder端序列中所有的词,是soft AM
局部注意力 Local Attention
本质上是Soft AM和 Hard AM的一个混合或折衷。一般首先预估一个对齐位置Pt,然后在Pt左右大小为D的窗口范围来取类似于Soft AM的概率分布。
注意力编码机制
编码:将神经网络中分散的信息聚集为某种隐层表示,形成信息量更丰富的表示,以便后继处理
注意力机制作为编码机制主要有:
编码为单一向量:
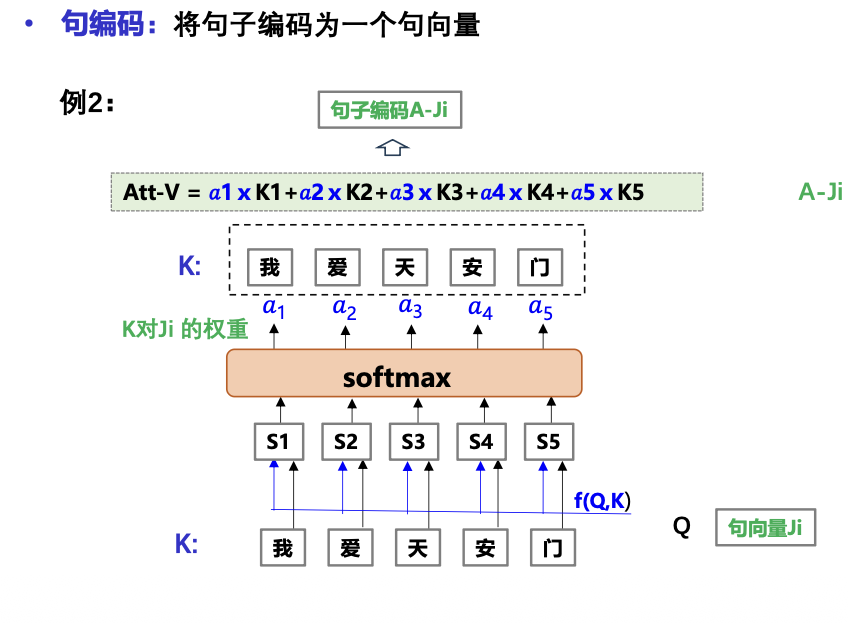
句编码:将句子编码为一个句向量
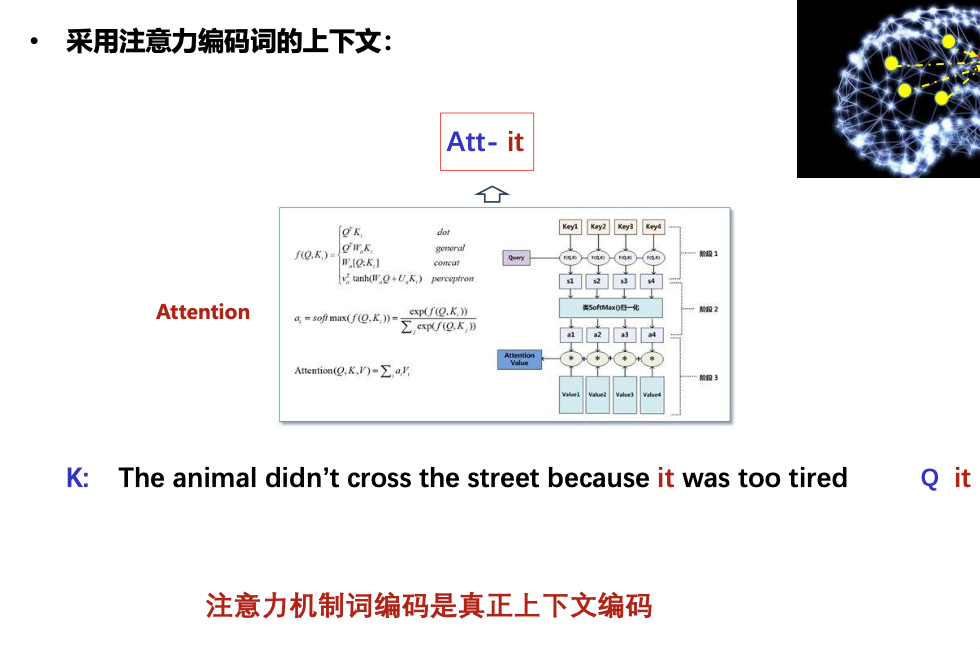
词编码 :将序列中的词进行词编码(编后词带有句子的各词权重信息)
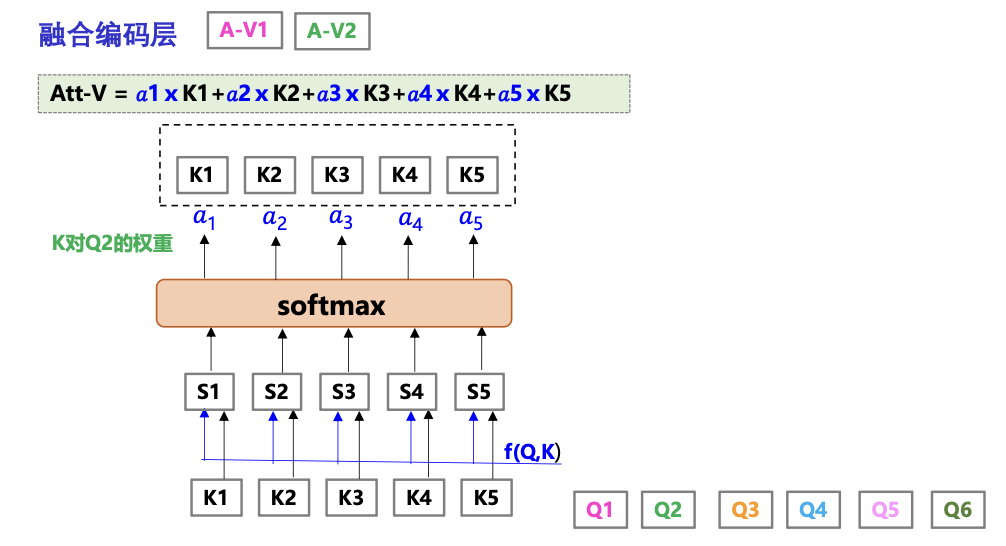
编码为一个序列:将2个序列编码为一个序列
- 不同序列融合编码:将2个不同的序列编码成二者的融合的表示序列,如,匹配任务和阅读理解任务常用的融合层表示
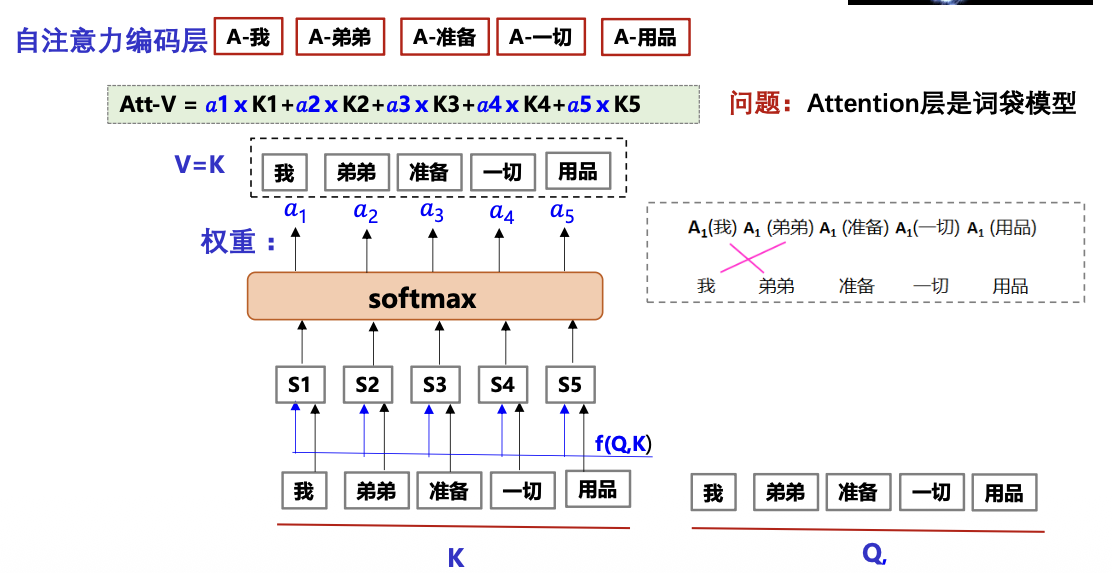
- 相同序列自注意力编码:利用多头自注意力编码对一个句子编码可以起到类似句法分析器的作用。如Transformer的编码端
编码为单一向量
注意力机制编码才是真正上下文编码

编码为一个序列
不同序列融合编码:将2个不同的序列编码成二者的融合的表示序列,如,匹配任务和阅读理解任务常用的融合层表示
相同序列自注意力编码:利用多头自注意力编码对一个句子编码可以起到类似句法分析器的作用。如Transformer的编码端
Attention(Q,K,V) 其中Q=K=V
多头注意力机制(Multi-Head Attention)
多头(Multi-Head)就是做多次同样的事情(参数不共享),然后把结果拼接
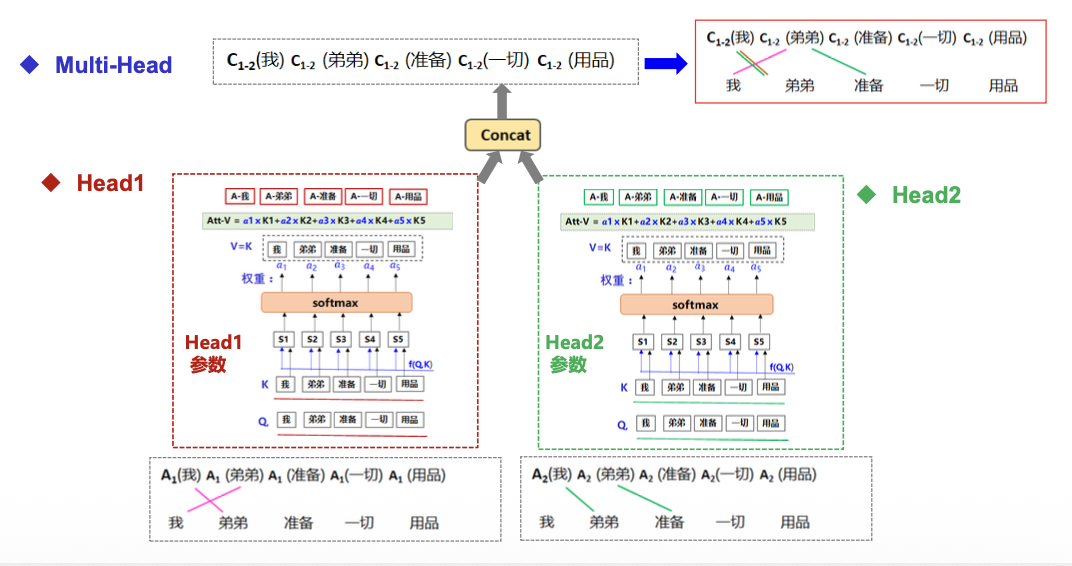
Attention的更详细解释。
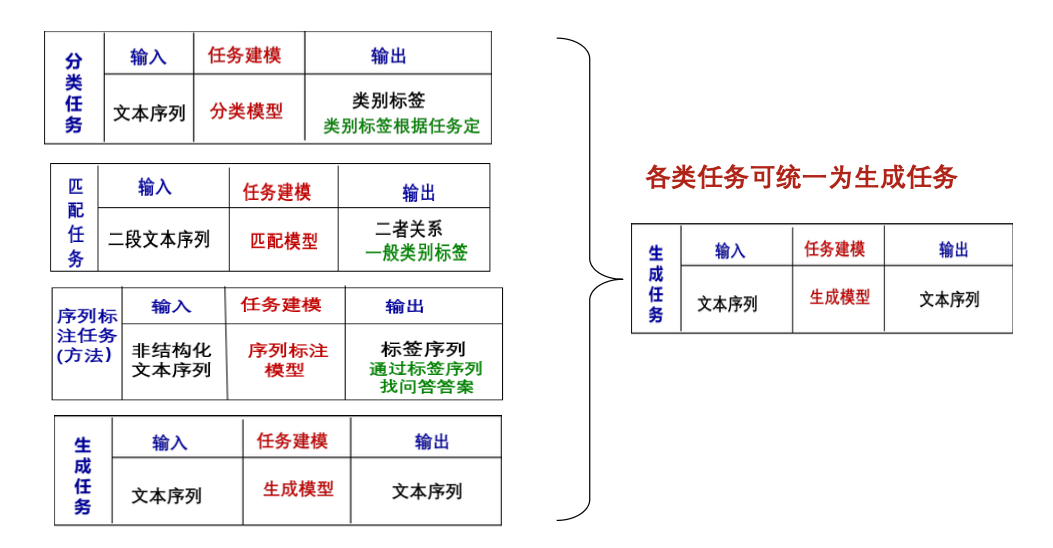
第六章 NLP基础任务
文本分类
利用计算机对大量的文档按照分类标准实现自动归类
序列结构文本分类框架(文本整体分类)
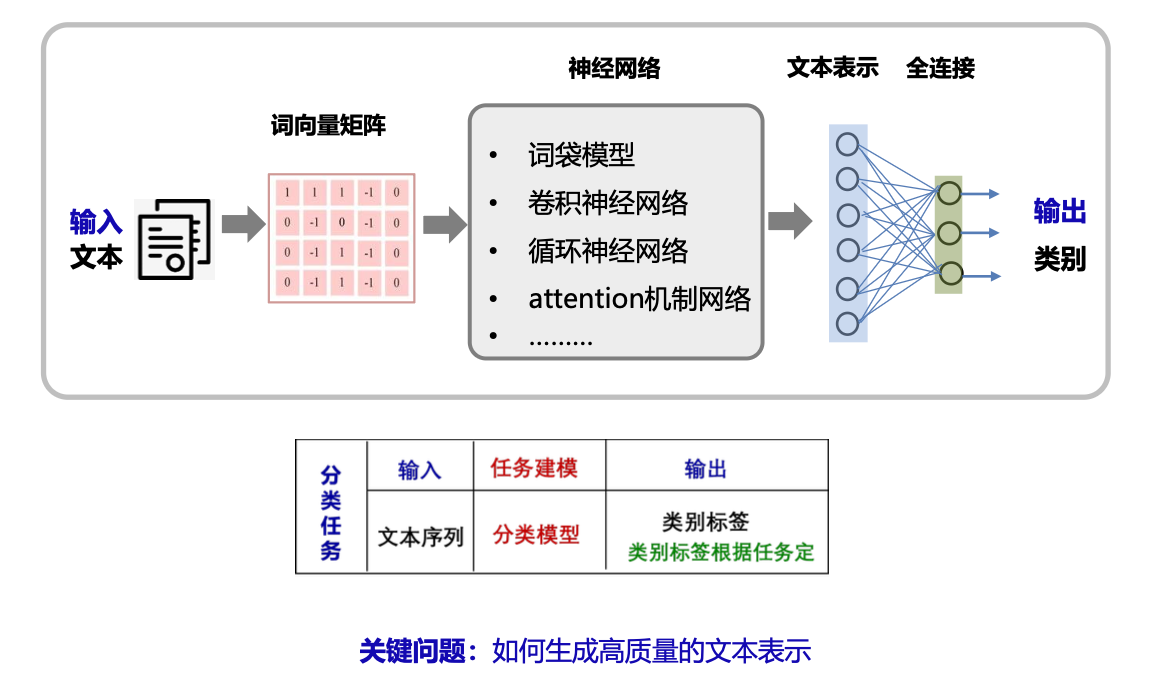
图卷积神经网络文本分类
文本匹配
研究两段文本之间的关系。一般将这类问题定义为“文本匹配”问题,匹配含义根据任务的不同有不同的定义。很多自然语言处理的任务都会涉及文本匹配问题
基于单语义文档表达的深度学习模型(基于表示-孪生网络)
基于多语义文档表达的深度学习模型(基于交互-交互聚合)
序列标注
输入:非结构化文本序列
输出:标签序列
标注问题是分类问题的推广,是复杂结构预测的简单形式(监督学习)
隐马尔科夫模型HHM(概率统计模型)
神经网络序列标注模型(深度学习模型)
双向RNN+softmax 模型
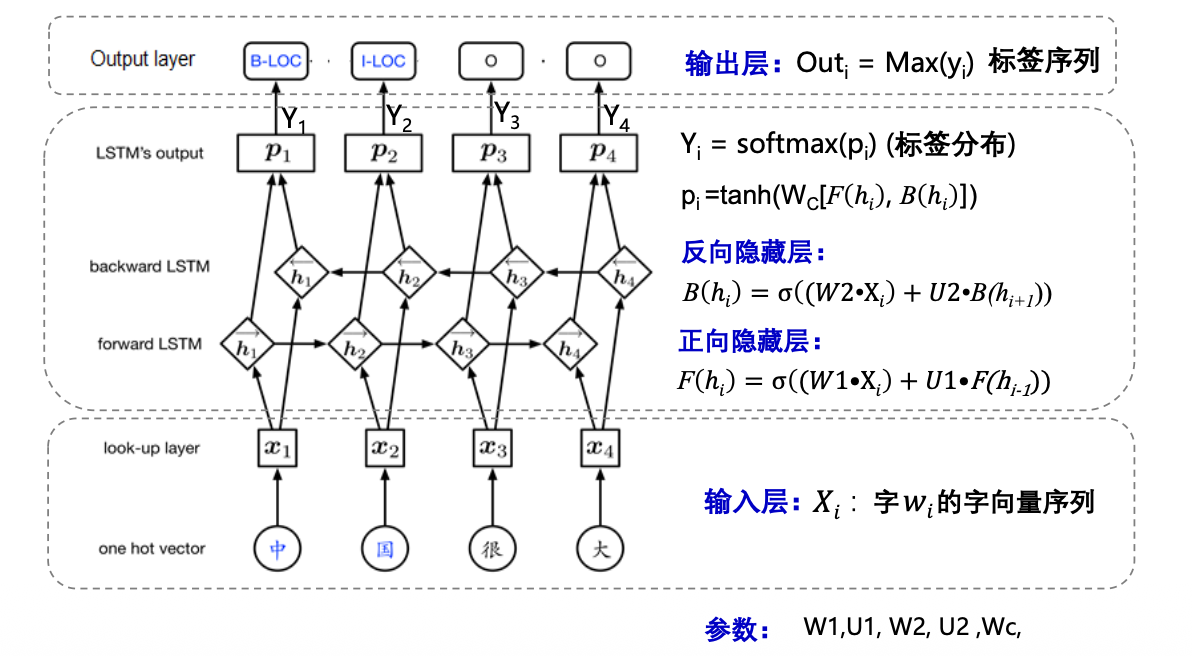
存在问题:输出独立(Yi之间没有关系)
BiRNN+CRF 模型
方法:设一组参数A学习标签间的转移概率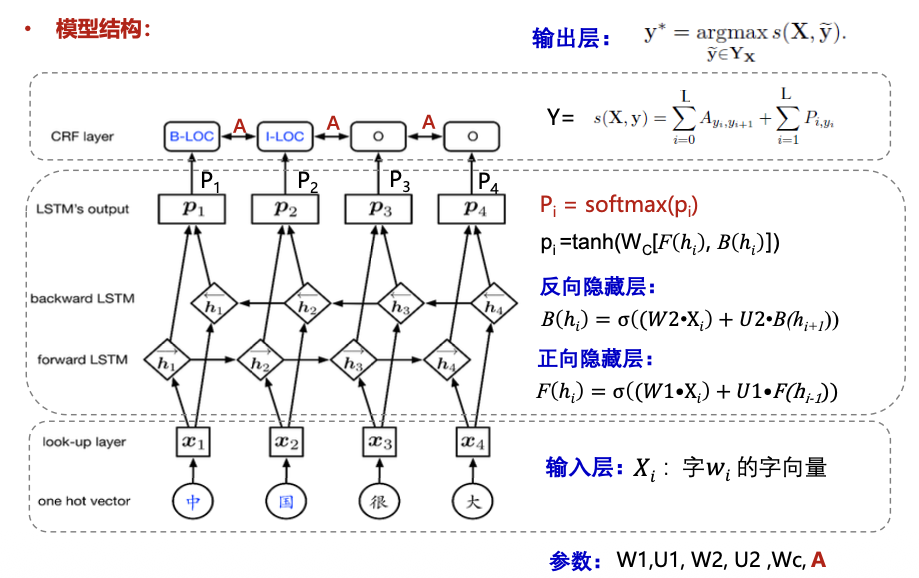
序列生成
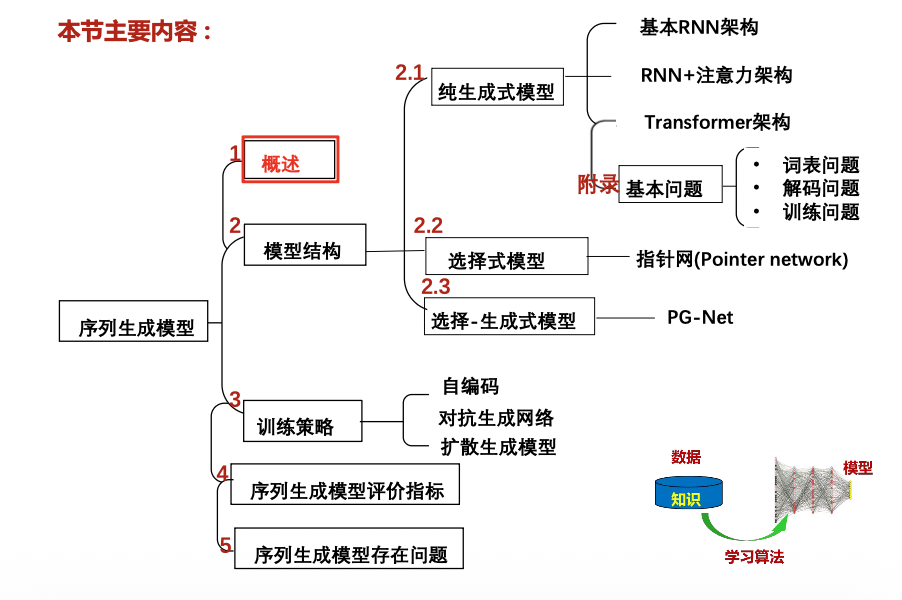
自回归序列生成: 用历史序列信息来预测序列中的下一个值的生成
条件序列生成:根据输入的内容X生成一串特定的序列Y(有监督任务)
可控序列生成:根据输入的内容X生成符合属性C的序列Y
Seq2Seq模型按输出生成方式
- 生成式模型Decoder:根据编码端形成的输入表示和先前时刻输出tokens,生成词表token的概率分布,并根据该分布产生当前输出词。( 编码端和解码端有各自词表,二者可相同或不同 。解码端需处理集外词OOV,一般用UNK 代替)
- 选择式模式Decoder:根据编码端形成的输入表示和先前时刻产生成的输出tokens,从输入端选择一个token作为输出 token ( 解码端和编码端词表相同)
- 选择-生成式模型Decoder:前两种方式结合,输出可以从输入中选择也可以由 Decoder 端生成。
模型结构
纯生成式模型结构——考点2
基本RNN架构
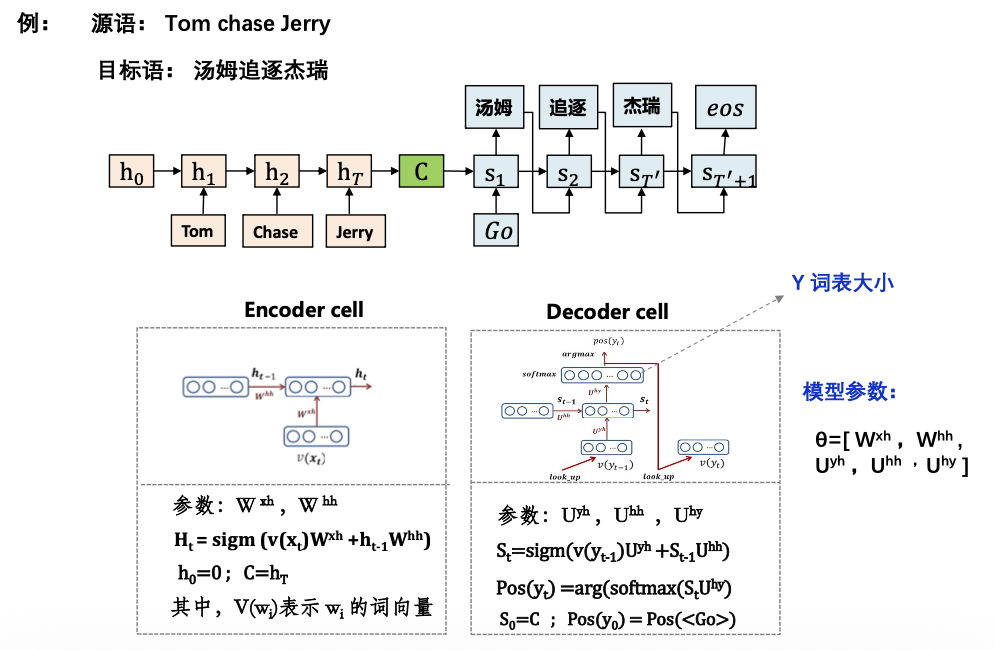
问题:对不同的输出 Yi 中间语义表示C相同。实际应该在翻译的时候,体现出英语单词对于翻译当前中文单词的不同程度的影响。
RNN + Attention
推敲网络:目前的序列生成方法往往通过一轮前向计算解码出整个目标序列,缺乏推敲过程。本文引入一个推敲网络进行双轮解码以模拟人类书写文章的过程,即先解码出一个基础序列,然后对其进行斟酌推敲形成最终的目标序列。
Transformer模型结构
模型特点:
全部采用Attention机制
克服了RNN无法并行计算的缺点,可以高度并行,训练速度快;
具有捕捉long distance dependency的能力,有较高的建模能力
训练:并行
预测:编码端并行,解码端串行
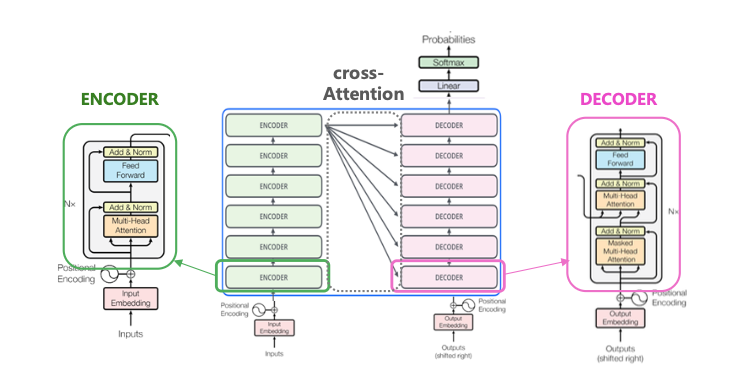
编码端:6层Attention堆叠,包含2个子层(Multi-head attention 和Feed Forward Network)
解码端:6层Attention堆叠,包含3个子层(Multi-head attention ,cross-attention和 Feed Forward Network)
交叉注意力部分:解码端的每一层与编码端的最后输出层做 cross-attention
训练——并行训练
Transformer mask机制
MASK 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。
Padding Mask
作用:处理非定长序列问题,使不定长序列可以按定长序列统一并行操作,在所有的 Scaled Dot-Product Attention 里面都需要用到。
Sequence Mask
作用:防止标签泄露 ,在 Decoder 的 Self-Attention 里面用到。
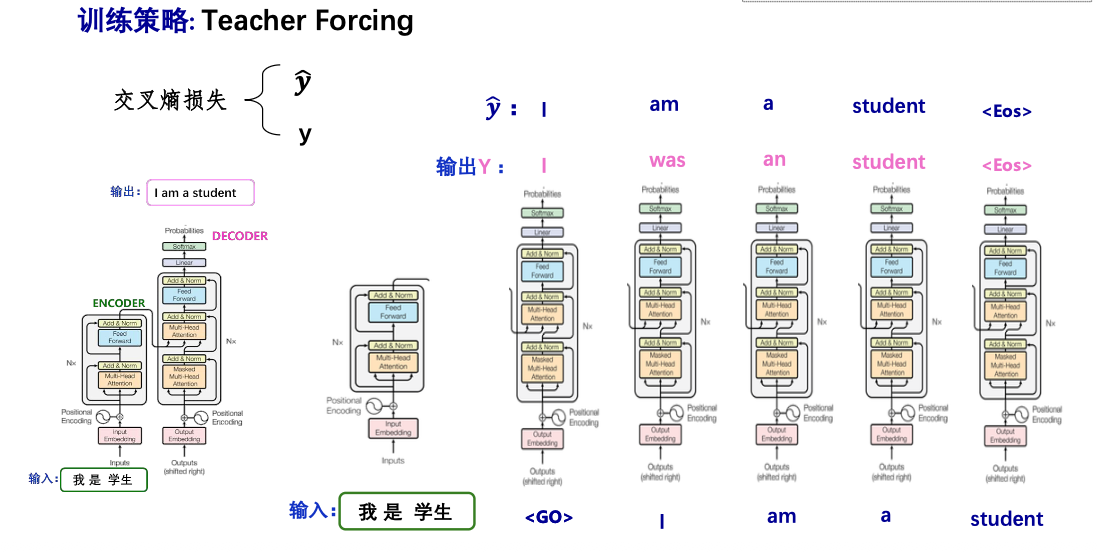
预测:
训练好的模型在预测时将源句子在编码端输入, encoder对其并行编码后得到编码端的输出tensor (不直接作decoder输入),然后Decode端进行解码,
步骤如下:
- 用起始符
当作decoder的 输入,得到输出 的第1个词 - 用
+ 已输出的词解码得到后继的输出词 - 重复2. 直至输出为结束符号
注:输入端编码并行进行,预测解码过程中,一个单词一个单词的串行进行输出。
生成式模型解码问题
生成模型解码方法:如何从生成 token 概率分布中选择下一个单词
贪心解码(Greedy Decoding):直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。
随机采样(Random Sampling):按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
Beam Search:维护一个大小为 k 的候选序列集合(一般为 5~10 ) ,每一步从每个候选序列的概率分布中选择概率最高的 k 个单词,然后保留总概率最高的 k 个候选序列。这种方法可以平衡生成的质量和多样性,但是可能会导致生成的文本过于保守和不自然。
top-k 采样 : 在每一步,只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。它允许其他分数或概率较高的token 也有机会被选中,有助于提高生成质量,但它可能会导致生成的文本不符合常识或逻辑。
top-p 采样(nucleus samplin): 每一步只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,因为它只关注概率分布的核心部分,可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
生成式模型词表问题
在神经网络生成模型(如机器翻译)中,由于考虑到计算的复杂度问题,都使用一个受限词表,这样会导致很多单词成了词表外的OOV(out of Vocablary)词,而这种OOV词在处理会产生问题并且打破了句子语义结构,增加了语句的歧义性,因此,如何处理罕见词和选择适当的词表是建模需要考虑的问题。
UNK处理:对于不在词表的OOV 词,用
**Wordpiece Model (子词方法)**基本思想:将单词拆分为更小的单元sub-word ,如“older”划分为“old” 和“er”,这些单元能组成其他词汇。由子词构成的词汇表可以有效的缓解词OOV问题和缩减词表规模提高处理效率。
拆分规则可以从语料中自动统计学习到,常用的是**BPE( Byte Pair Encoding )**编码法
BPE是一种数据压缩的算法,它通常用于自然语言处理领域中的词汇表构建(处理罕见OOV词)等任务
算法的核心思想:根据语料通过不断地合并字符或子词来生成关于语料的词汇表
Normalization
Pre-tokenization(统计语料中字符频率-用Pre-token表记录)
将第2步Pre-token表单词拆分为单个字符,单词后加结束符 ,并将该步所有字符加入词汇表
计算Pre-token表中二个相连字符/片段的出现频率 ,将共现频率最高的二个字符/片段用频率表保存
将4中频率表中的二字符合并, 将合并后的字符/片段 加入词汇表,并将Pre-token表记录中该相连的片段合并,形成新粒度的Pre-token表记录
转步骤 4 ,直至得到希望大小的词汇表
生成式模型训练问题
选择式模型
纯生成式模型特点:预测输出端词表的大小是固定的,输出 toke 是输出词表中概率最大的。这样就无法解决输出词表需按输入情况动态变化的问题。
例如:凸包问题。输出是输入的子集。
指针网络:特点:Yi 从X 的标识词典中产生
选择-生成式模型
指针网络(选择式模型)特点:输出直接从输入中选择,输出词表与输入词表相同,无法处理输出需要产生输出词表以外词的情况。
PG-Net
指针生成器网络(Pointer-generator network)
基本思想:将编码-解码+注意力模型和指针网结合,生成既可产生也可选择的输出
特点:Yi 既可以从输入端X 的标识词典中产生也可以从输出端Y 的标识词典中产生,这样既可以生成高质量的摘要,也可以处理原文中的未登录词(OOV)
训练策略
自编码:作为一类神经网络结构在无监督学习中用于有效编码。通常用于降维。近期,自编码的概念广泛地用于数据的生成模型。
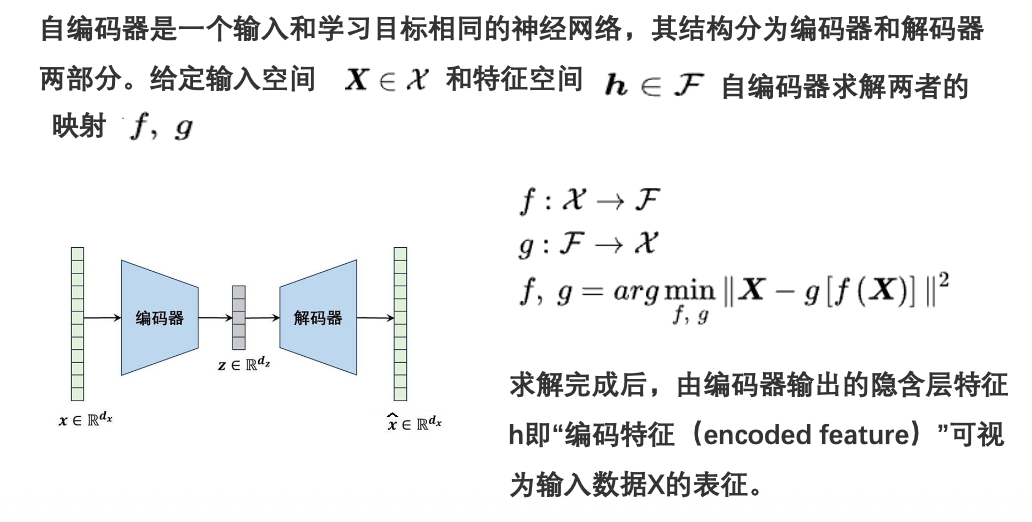
深层自编码器
变分自动编码模型(VAE)
降噪自编码
生成对抗网络(GAN)
- 由生成器产生一组数据
- 对生成器产生的数据和真实数据进行标注
- 用步骤2 产生的标注数据训练判别器
- 训练生成器器
- 重复
扩散模型(Diffusion扩散模型)
评价指标——考点2
正确率 (precision, P) :测试结果中正确切分的个数占系统所有输出结果的比例
召回率(Recall ratio, R):测试结果中正确结果的个数占标准答案总数的比例
BLEU
BLEU(Bilingual Evaluation Understudy)是衡量模型生成序列与参考序列之间的N元词组(N-Gram)的重合度,最早用来评价机器翻译模型的质量,目前也广泛应用在各种序列生成任务中。
基本思想 :假设模型生成一个候选(Candidate)序列𝐱,真实数据中存在一组参考(Reference)序列,生成序列与参考译文相比较,越接近,生成序列的正确率越高。
实现方法 :统计同时出现在生成序列和参考序列中 的 n 元词的个数,最后把匹配到的n 元词的数目除以生成序列单词数目,得到评测结果( 𝒏 元组集合的精度)

ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)最早应用于文本摘要领域。和 BLEU类似,但 ROUGE计算的是召回率(Recall)。假设模型生成一个候选(Candidate)序列𝐱,真实数据中存在一组参考序列,我们首先从候选序列中提取𝒏元组集合𝓦

问题
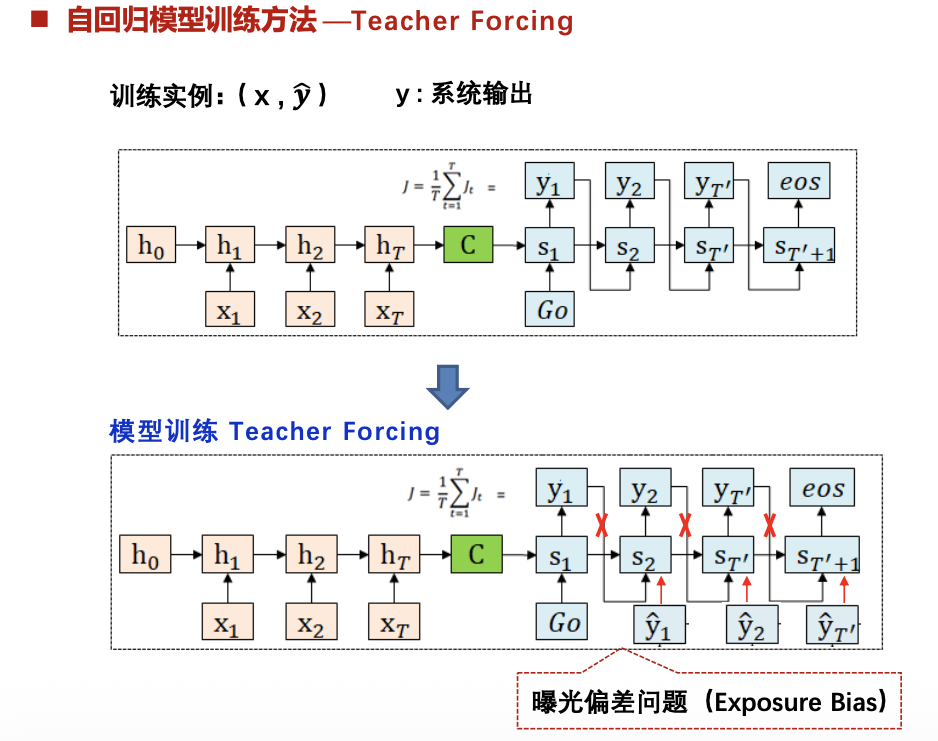
曝光偏差问题(Exposure Bias):模型生成的分布与真实的数据分布并不严格一致。一旦在预测前缀𝒚𝟏:(𝒕−𝟏)的过程中存在错误,会导致错误传播,使得后续生成的序列也会偏离真实分布。这个问题成为曝光偏差(Exposure Bias)
解决方法:Scheduled Sampling:在训练过程中,混合使用真实数据和模型生成数据 。(逐步减少)
训练-评价目标不一致的问题:序列生成模型一般采用和任务相关的指标来进行评价,比如BLEU、GOUGE等,而训练时使用最大似然估计,这导致训练目标和评价方法不一致。而这些评价指标一般都是不可微的,无法直接使用基于梯度的方法来进行优化。
解决方法:可采用强化学习的策略进行模型训练
第七章 预训练语言模型
预训练模型概述——考点3
浅层模型的缺点
word2vec无法捕获一词多义的情况,无法根据下游任务进行调整
如果一个词没有根据下游任务改变自己的能力,就需要设计复杂模型在下游任务里使用词向量来展示不同层面的特征
从一开始就让词向量拥有可以根据不同下游任务而变换的能力?
ELMo
ElMo使用双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数是取这两个方向语言模型的最大似然
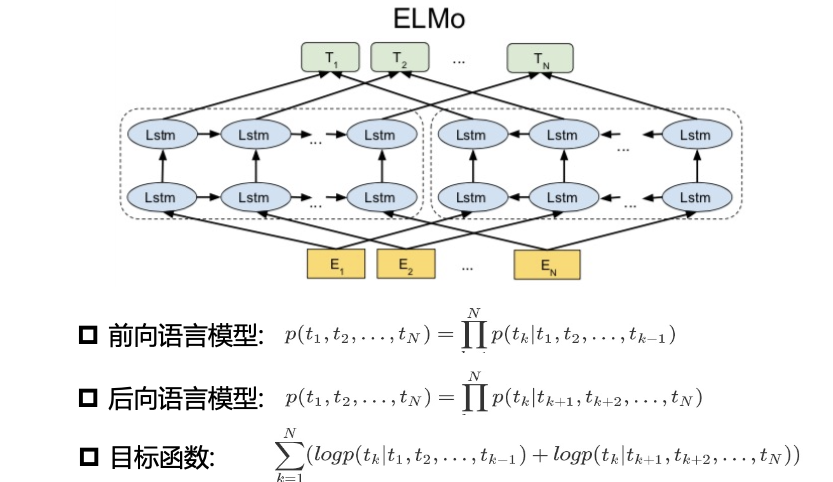
ELMo给原始词向量层和每个LSTM隐层都设置了一个可训练参数,每层BiLSTM学习不同特征,不同下游任务对每层的权重也不同
可以将各层的输出作为最后的输出,或将各层的输出进行组合作为最后的输出,将学习到的向量表示输出给下游任务
问题:
- 不完全双向:前向和后向LSTM两个模型分别训练,得到的隐层向量直接拼接得到结果向量;Loss function是前向和后向的loss function直接相加,并非完全同时的双向计算
- 自己看见自己:要预测的下一个词在给定的序列中已经出现,而传统语言模型的数学原理决定了它的单向性
- 使用LSTM:无法并行化、特征提取能力不够
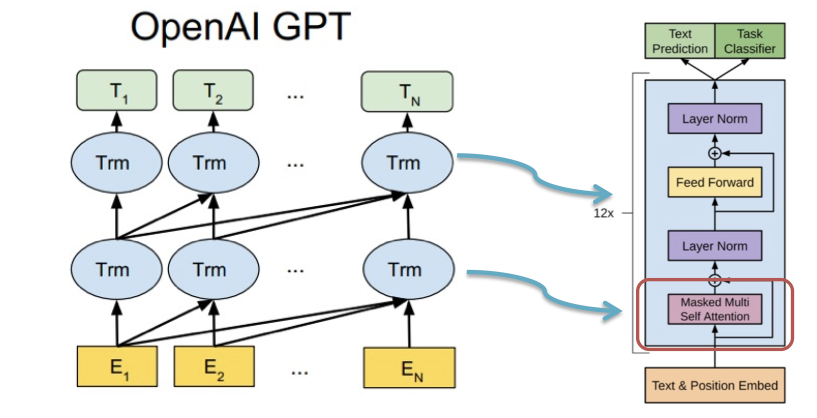
GPT
使用Transformer作为RNN的替代结构,仅采用decoder部分Mask Multi-Head Attention结构,避免“自己看见自己”问题
只采用上文词来预测当前词,不再考虑下文词
在Fine-tune阶段,将预训练模型提供给下游的任务,预训练模型与下游任务模型联合优化
Bert
使用堆叠的双向Transformer Encoder,在所有层中共同依赖于左右上下文,不用Decoder
Pre-training和Fine-Tuning阶段使用相同的模型结构
同样的Pre-trainng模型参数可用于初始化不同下游任务模型
预训练在微调时可以仅通过使用一个额外的输出层就可以达到最好的效果
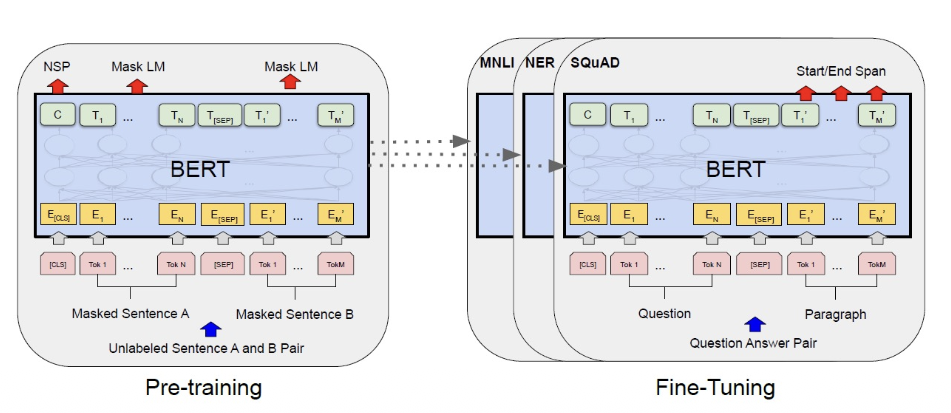
预训练策略
- 看不见自己:MLM:随机屏蔽部分输入token,然后只预测那些被屏蔽的token
- 建模句间关系:NSP预训练句子关系模型,使用二元分类任务预训练句子关系模型
第三范式:预训练,精调范式
如何在有限的人工标注数据集下训练有效的深度神经网络模型->迁移学习
源任务和目标任务具有完全不同的数据领域和任务设置,但是处理任务所需的知识是一致的
迁移学习有两种常用的预训练方法,包括特征迁移和参数迁移
- 特征迁移是在预训练阶段训练有效的特征表示(跨领域和任务地预编码知识),然后在目标任务使用(例如word2vec\elmo\glove等)
参数迁移假设源任务和目标任务可以共享模型参数或超参数的先验分布。在预训练阶段将知识编码进共享的模型参数中,在目标领域微调参数(Bert、 RoBERTa、GPT、XLNET、T5)
大规模预训练模型的效果源于其精细化的预训练目标和大量的模型参数:在预训练阶段,将学习到的大量知识均存储在参数中;在fine-tuning阶段,将这些知识(学习到的模型)应用到下游任务中,并发挥作用
改进模型结构和预训练任务:统一序列建模;认知驱动建模;新的预训练任务
利用更丰富的数据资源:1.多语言语料;2.知识图谱;3.多模态数据
优化计算效率和性能:1.系统级优化;2.学习算法优化;3.模型压缩
第四范式:预训练,提示,预测范式——考点5
提示学习
是指在模型推理过程中,不改变模型参数,通过prompt引导模型完成任务(激发模型能力)
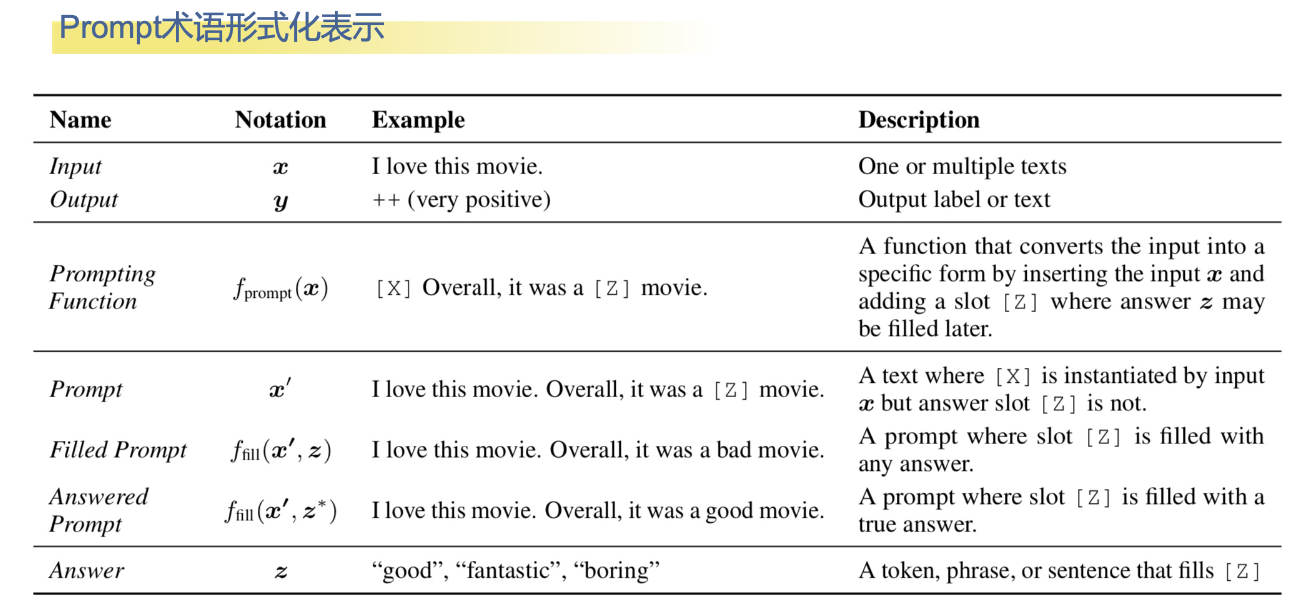
提示学习设计原则
预训练模型选择:PLM模型结构多样,同时预训练任务也各有特色,选择与特定任务匹配的PLM模型十分必要
Prompt Engineering:针对不同任务,选择对应合适的Prompt输入至关重要(槽Prompt,前后缀Prompt)
Answer Engineering:主要涉及模型输出的粒度形式(token,span,sentence,etc.)及模型输出到实际标签的映射方式
Multi-Prompt Learning:相对于Single Prompt, Multiple Prompt学习能在一定程度上提升最终效果
Training Strategies:训练Prompt的方法多种多样,LM参数及Prompt参数可进行多种组合训练
上下文学习
上下文学习使用由任务描述和(或)示例所组成的自然语言文本作为提示
示例选择:通过自然语言描述任务,从任务数据集中选择一些样本作为示例
示例格式和顺序:根据特定的模板,将这些示例按照特定顺序组合成提示内容
将测试样本添加到提示后面,整体输入到大语言模型以生成输出

示例选择:
基于相关度排序的方法:如k近邻方法:使用文本嵌入模型将所有候选样本映射到低维嵌入空间中,然后根据这些候选样本与测试样本的嵌入语义相似度进行排序,并选择出最相关的k个示例
基于集合多样性的方法:针对特定任务选择出具有代表性的、信息覆盖性好的示例集合,从而确保所选示例能够反应尽可能多的任务信息,除了考虑样本与目标任务的相关性,同时也要考虑与已选样本的相似性。 例 如 , 可以采用经典启发式MMR算法或基于行列式点过程的DPP算法,增强示例集合的多样性
基于大语言模型的方法:将大语言模型作为评分器对候选样本进行评估,进而选择出优质的示例

示例顺序
产生候选示例顺序
- 基于随机选择的方法:枚举给定示例的所有可能排列组合,然后从中随机选取一种排列作为示例的顺序
- 基于语义相似度的方法:根据示例与测试样本之间的语义相似度进行排序,然后将与测试样例相似度更高的示例放在更靠近测试样本的位置
评估示例顺序质量
- 基于数据集的方法:采用测试集或人工创建的验证集,测试大语言模型基于该示例顺序的任务性能,以此作为当前示例顺序的评分
- 基于结果不确定性的方法:采用模型对于预测结果的不确定性作为评估指标,计算基于该示例顺序大语言模型预测分布的熵值,选择熵值较低的示例顺序作为较为有效的顺序。熵值越低,意味着模型预测分布越不均匀,则模型预测的置信度更高
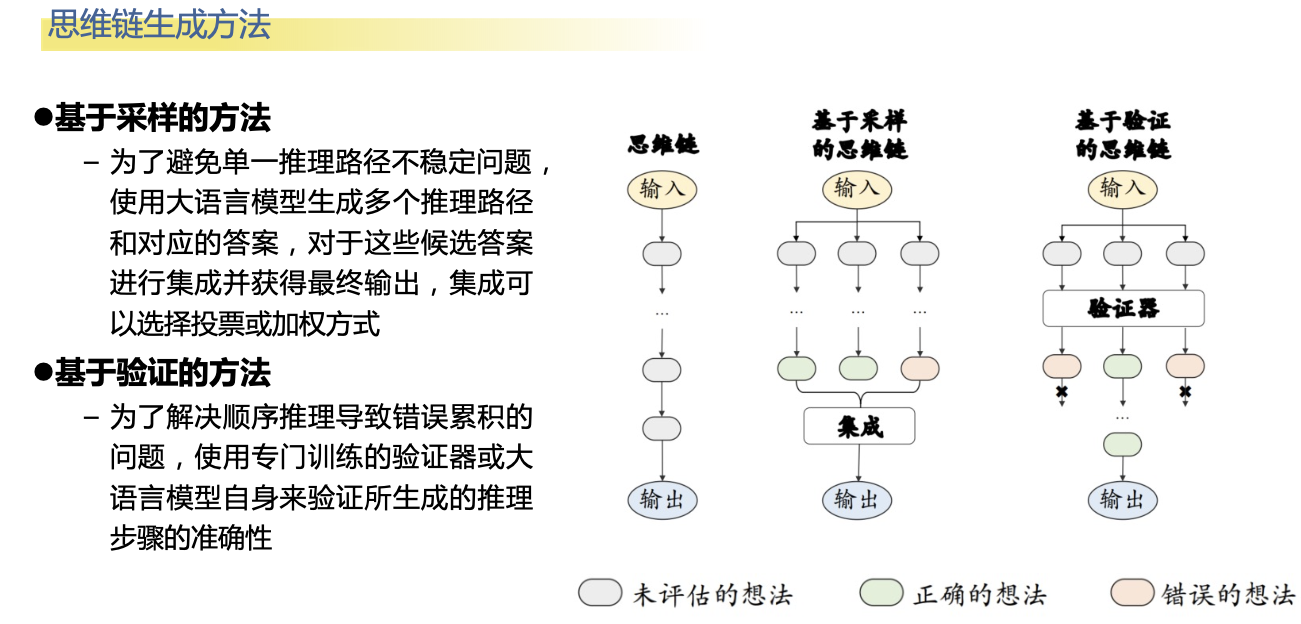
思维链提示
思维链提示旨在增强大语言模型在各类复杂推理任务上的表现,常见的推理任务包括算术推理、常识推理以及符号推理等。将上下文学习中<输入,输出>映射关系转换为<输入,思维链,输出>三元组形式,进一步融合了中间的推理步骤来指导从输入到输出的推理过程
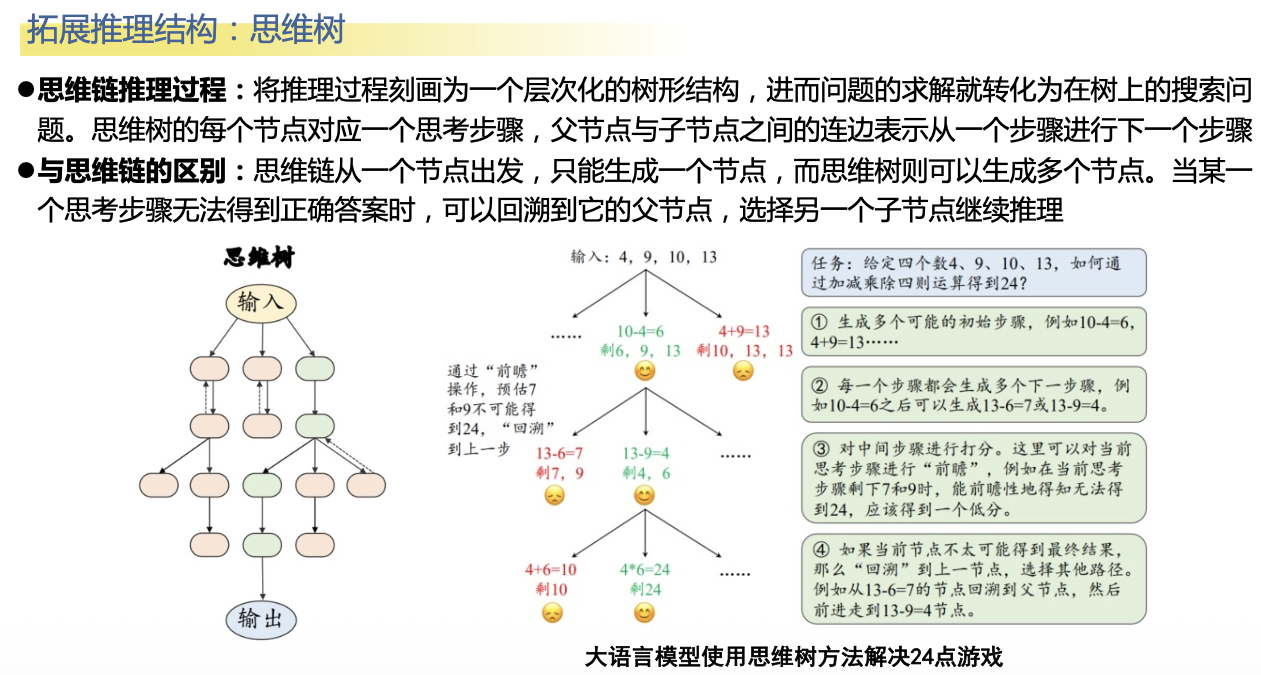
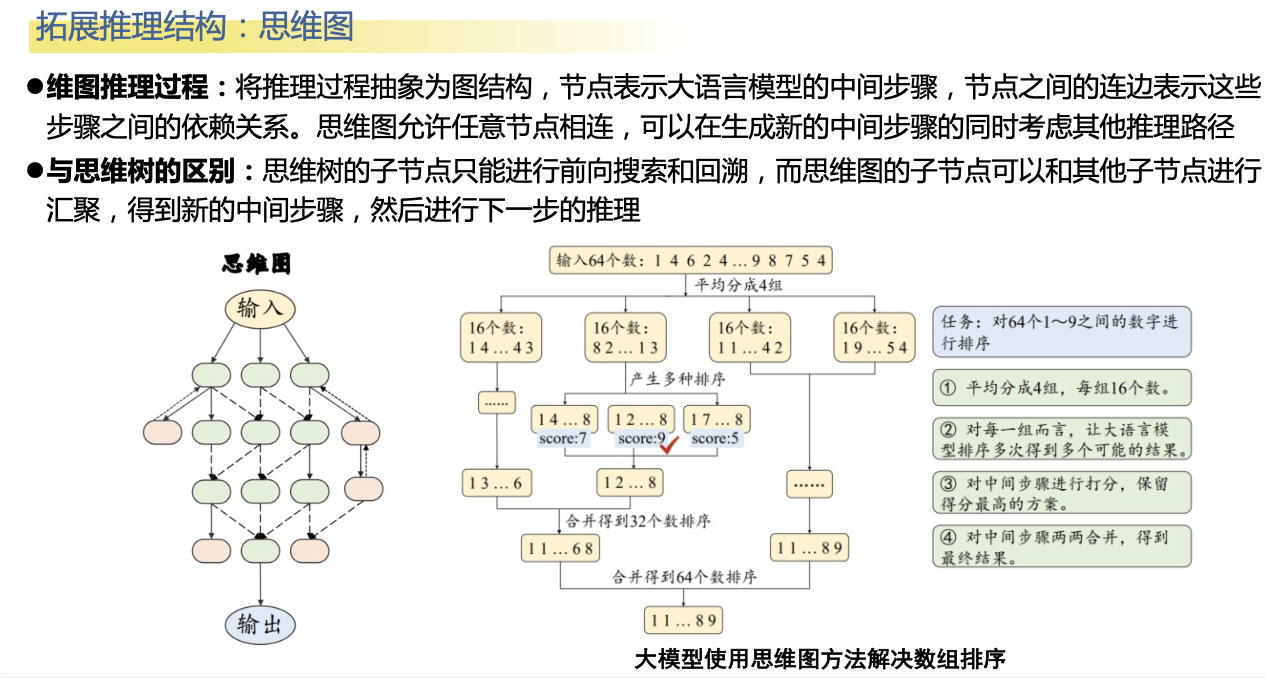
第五范式:大模型
大模型的一些技术
第八章 情感分析
其他内容不考就没看(太多了)
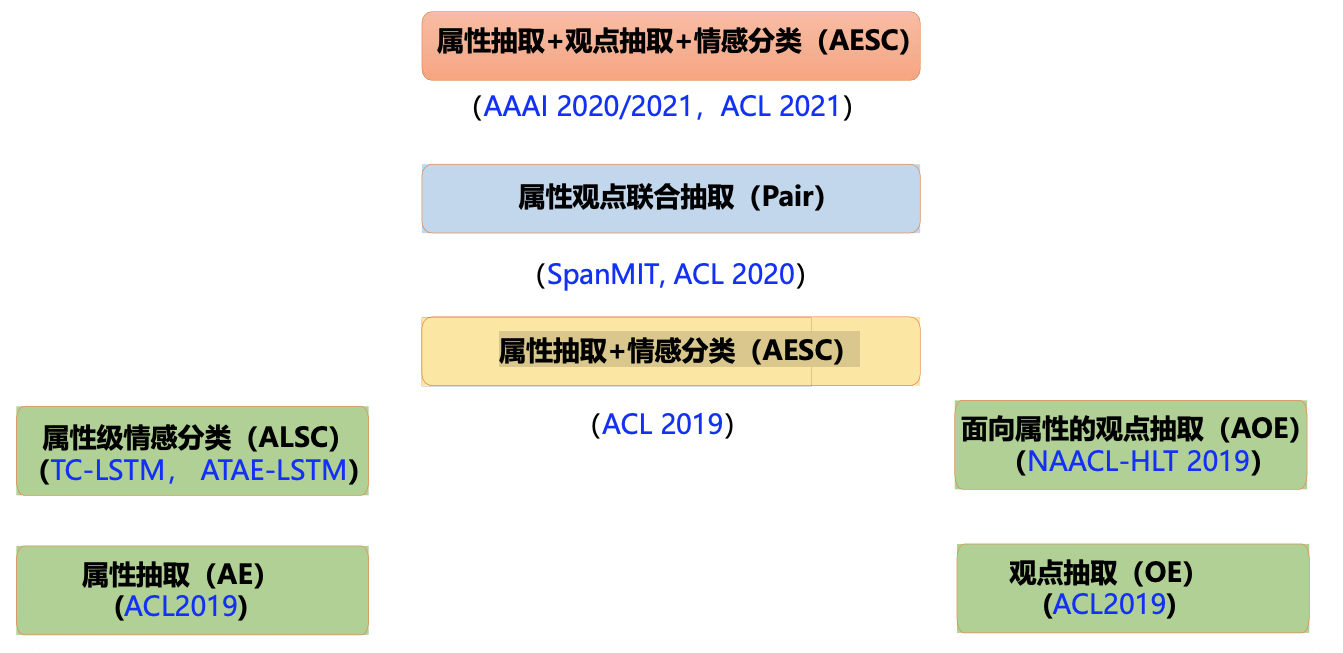
属性级情感分类——考点8
细粒度属性级情感分类是指判断评价对象及其属性的情感倾向
任务定义
基于属性的情感分析/Aspect-based Sentiment Analysis(ABSA)
- 更精细的情感分析,为每个实体(及其属性)识别情感
- 更好地理解主观性文本的情感分布
任务形式:
- Aspect-Extraction,识别给定文本中提到的Aspect
- ABSA,确定Aspect 的情感方向
通常存在两类观点,属性级情感分类关注的观点为常规型观点
- 常规型观点(Regular Opinion):对某些目标实体的情绪/意见表达
直接观点:“华为P50触摸屏真的很酷。
间接观点:“服药后,我的疼痛消失了。
- 比较型观点(Comparative Opinion):多个实体的比较。
(e,a,s,h,t)
| 元素 | 含义 |
|---|---|
| e | 观点评价的目标实体 |
| a | 实体 e 中一个观点评价的实体属性 |
| s | 对实体 e 的 a 属性的观点中所包含的情感 |
| h | 观点持有者 |
| t | 观点发布时间 |
s可以是正向(褒义)、负向(贬义)、中立的,或是一个1~5的打分。
建模

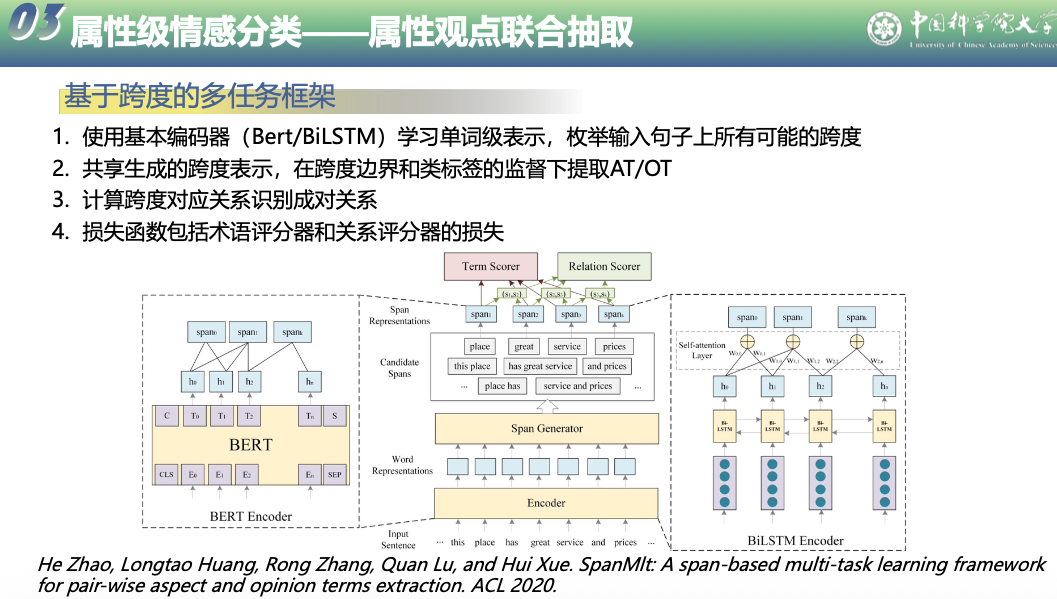
第九章 信息抽取
实体识别——考点7
传统命名实体识别任务:实体之间是非重叠的且由句子中连续的片段构成(平面实体)
限定实体类别:限定识别七类命名实体(人名、 机构名、 地名、 时间、日期、 货币和百分比)
限定目标文本:封闭文本语料(有标注-有监督学习)
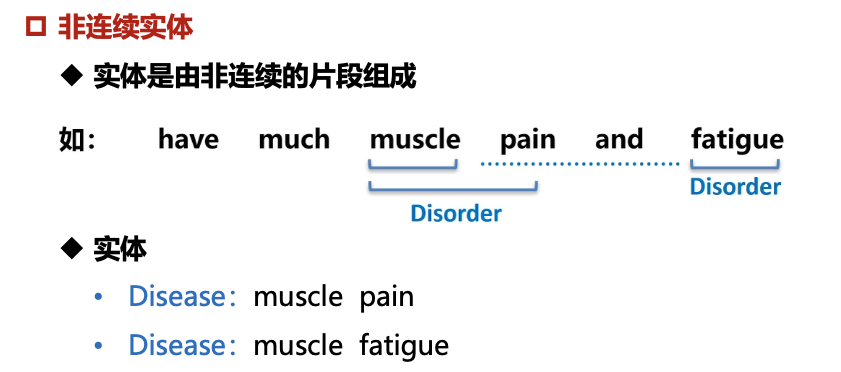
复杂命名实体识别任务:传统的命名实体识别难以适用于复杂的抽取场景,复杂实体之间可能存在嵌套、重叠的结构或是实体由非连续的片段组成
限定实体类别:类别根据具体任务而定
限定目标文本:封闭文本语料(有标注-有监督学习)
开放域实体抽取任务
不限定实体类别:可以是任何类型的实体,如维基百科条目等
不限定目标文本:大规模开放语料,如Web页面、真实世界信息(无标注)
复杂实体实体识别——嵌套实体
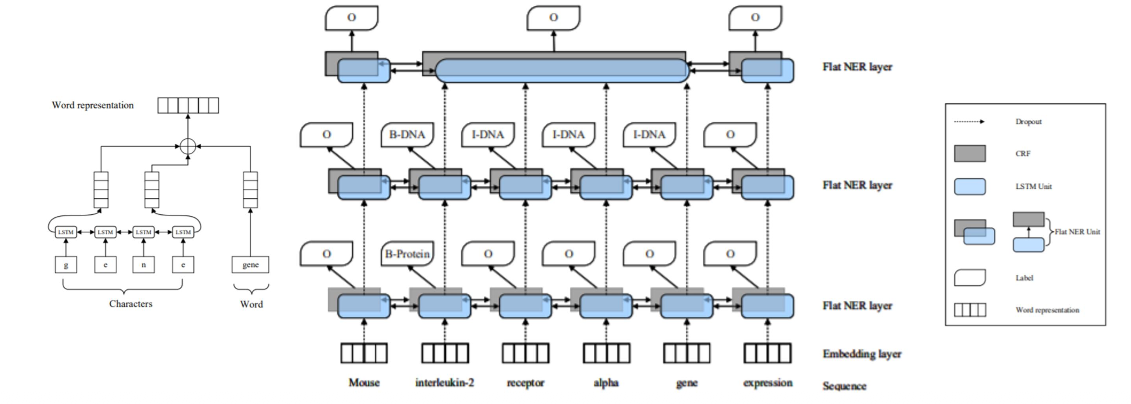
- 基于序列转换的方法:将含有嵌套实体的序列转换成不含嵌套结构的超图/序列
基本思想:通过堆叠平面NER层(BiLSTM+CRF)识别不同层实体,先识别最内层实体,然后将上一层的输出合并至当前平面NER层,逐层识别
输入输出:句子,每个嵌套层的标注序列
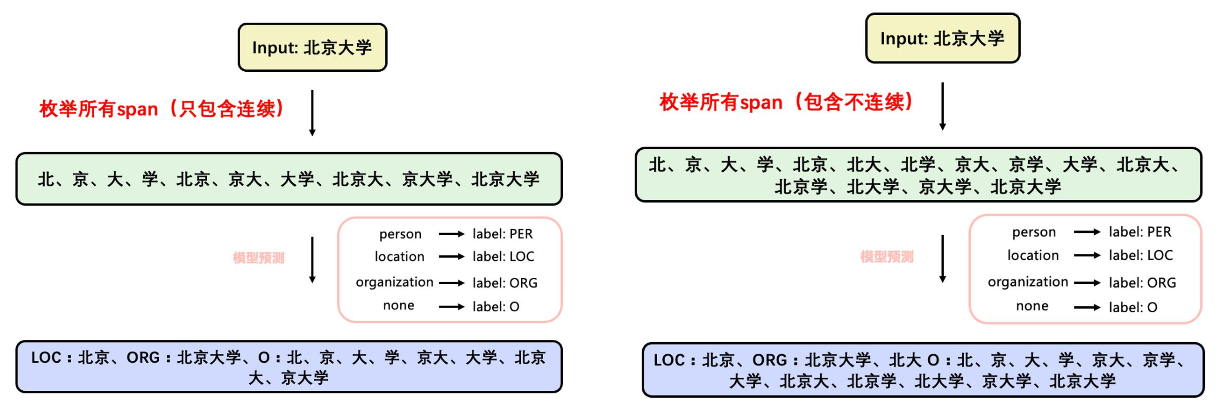
- 基于span分类的方法:识别出所有可能的实体span,然后对每个span进行分类
span指由若干个词组成的实体片段,可通过枚举⼀个序列中的所有span先确定实体的边界,再利用模型分类得到实体的类型
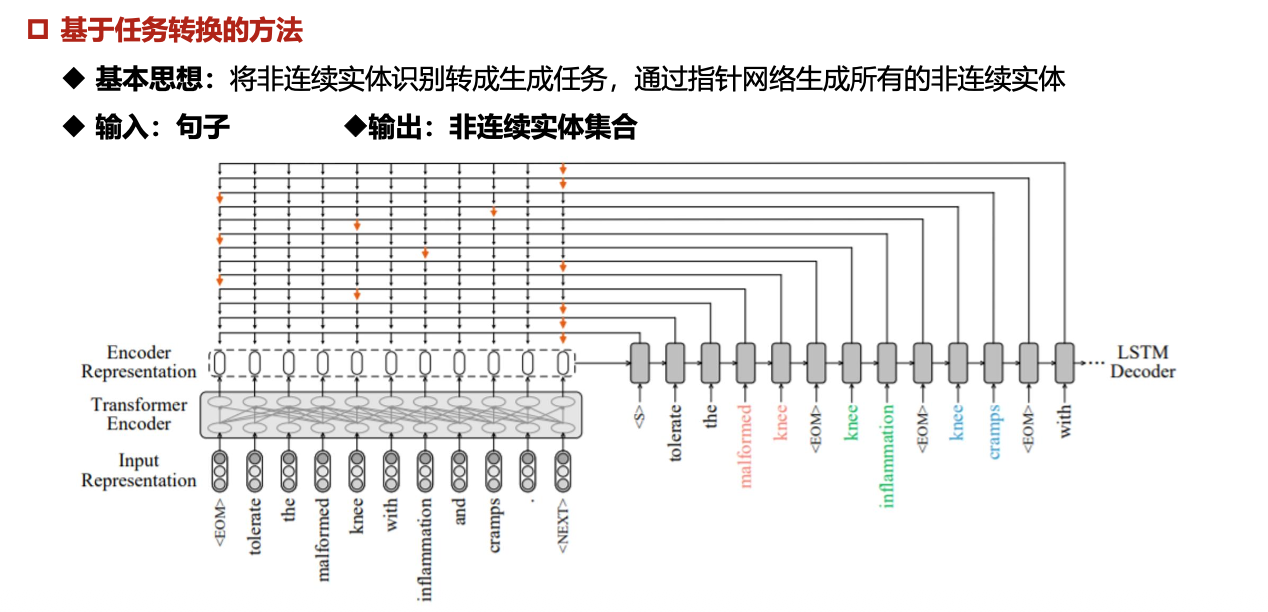
- 基于任务转换的方法:将实体识别转换成其他任务进行处理,比如阅读理解、机器翻译、依存树解析等
基本思想:将嵌套实体识别任务转换成抽取式的阅读理解任务,通过为每个实体类型创建一个问题模板来提供先验知识
模型输入:句子+预定义的实体类型问题
模型输出:句子中所对应问题的答案范围

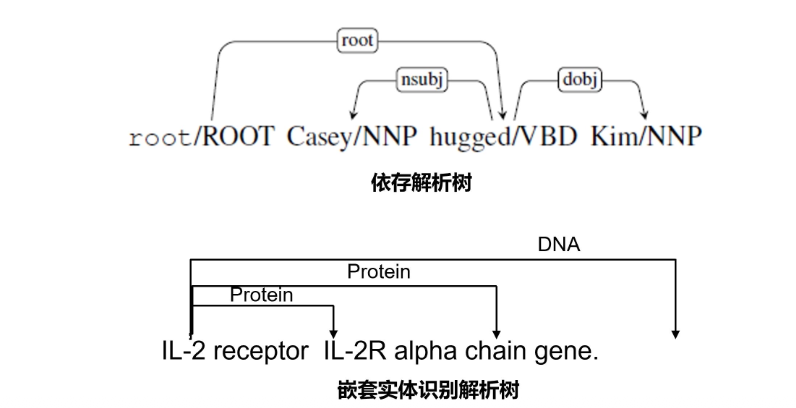
- 基于任务转换的嵌套实体识别方法:基于Dependency Parsing 的方法
基本思想:将嵌套实体识别任务转换成抽取式的依存解析的任务
模型输入:句子
模型输出:句子中任意两个词之间是否存在依赖边以及依赖边的类型
复杂命名实体识别——非连续实体
非连续命名实体识别方法
基于序列标注的方法
基于超图的方法
基于转换的方法
基于span分类的方法
事件抽取——考点6
事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变
主要研究如何从描述事件信息的文本中抽取出用户感兴趣的事件信息并以结构化的形式呈现出来
本质:从无结构化数据中抽取结构化事件信息
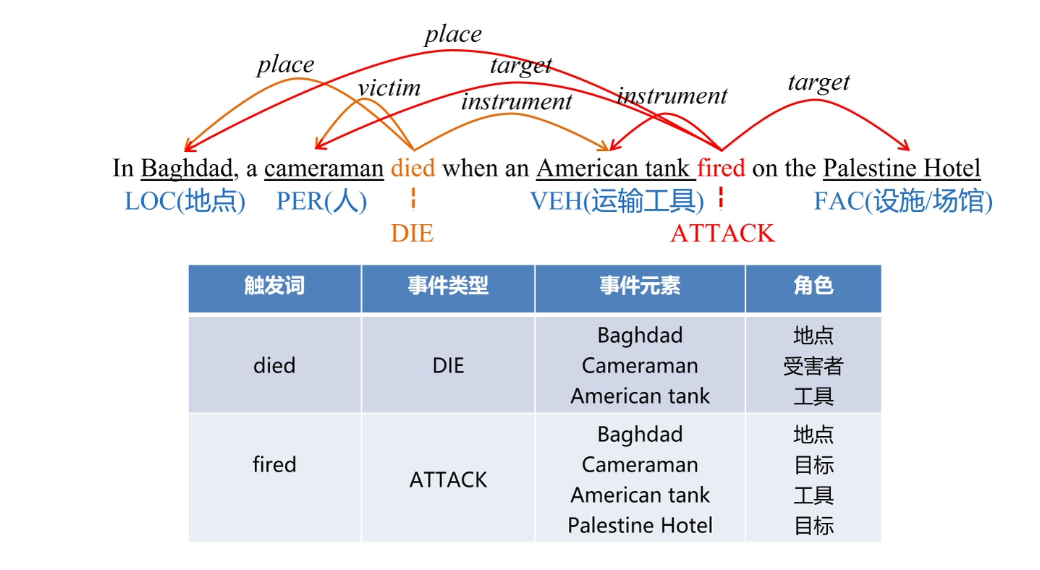
事件描述(Event Mention):是指对一个客观发生的具体事件进行的 自然语言形式的描述,通常是一个句子或者句群
事件触发词(Event Trigger):是指一个事件描述中最能代表事件发生的词,是决定事件类别的重要特征,往往是动词或者名词
事件元素(Event Argument):是指事件中的参与者,是组成事件的核心部分,它与事件触发词构成了事件的整个框架
元素角色(Argument Role):是指事件元素与事件之间的语义关系, 也就是事件元素在相应的事件中扮演什么角色
事件类别(Event Type):事件元素和触发词决定了事件的类别
事件抽取任务
事件监测:触发词识别、触发词类型识别
元素抽取:元素识别、元素角色分类
Pipeline Approach:将整个任务分成若干子任务,依次进行求解
- 优点:能够简化整个事件抽取任务
- 缺点:级联错误
Joint Approach:同时提取所有信息的模型
- 优点:能够产生Triggers与Arguments之间的双向信息流交互
- 缺点:联合模型更复杂,泛化性能差
句子级事件抽取
文档级事件抽取
第十章 智能问答系统
任务型智能对话系统——考点9
该系统旨在帮助用户完成特定领域的特定任务,如餐厅预订、天气查询、航班预订等,在实际业务中具有重要价值。这类对话往往涉及一系列的步骤或者子任务来帮助实现最终的任务目标
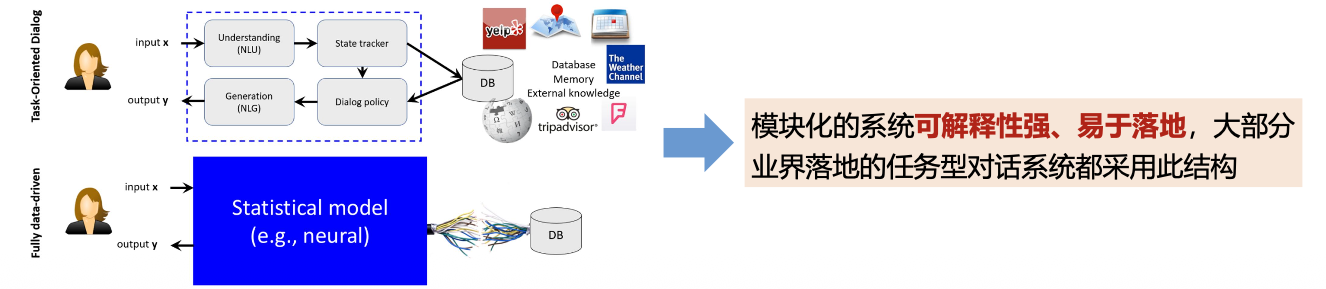
分类:流水线系统、端到端系统
模块化的任务型对话系统
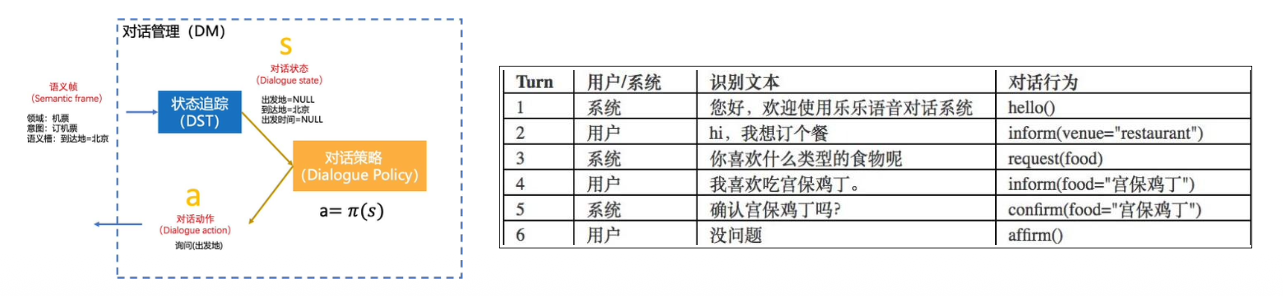
- 自然语言理解(Natural Language Understanding, NLU):对用户的文本输入进行识别解析,得到槽值和意图等计算机可理解的语义标签。
- 对话状态跟踪(Dialog State Tracking, DST):根据对话历史,维护当前对话状态,对话状态是对整个对话历史的累积语义表示,一般就是槽值对(slot-value pairs)。
- 对话策略学习(Dialogue Policy Learning, DPL):根据当前对话状态输出下一步系统动作。一般对话状态跟踪模块和对话策略模块统称为对话管理模块(Dialogue manager, DM)。
- 自然语言生成(Natural Language Generation, NLG):将系统动作转换成自然语言输出。
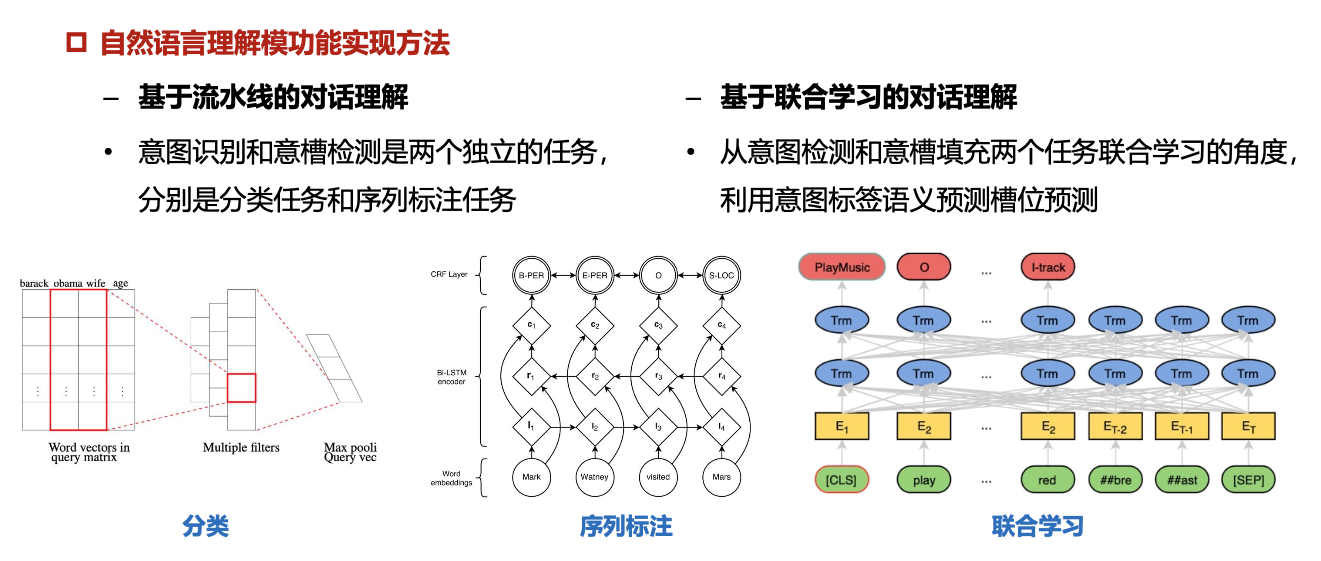
自然语言理解模块NLU
两个子任务:意图识别(intent detection)+ 槽位填充(slot filling)
槽是多轮对话过程中将用户意图转化为明确用户指令所需要补全的信息
利用用户对话中关键词填写的槽叫做词槽,利用用户画像以及其他场景信息填写的槽叫做接口槽
相比于命名实体识别,槽值的预测更能反应用户的需求或目标

对话管理(DM)模块
对话状态追踪(dialog state tracking, DST)维护 & 更新对话状态
- 对话语言理解(NLU)只能获取句子级的用户意图和槽位,考虑到对话常常是多轮交互的,还需要动态更新追踪用户需求及其变化 (记录并更新槽位信息)
对话策略学习(dialog policy learning)
- 根据 DST 中的对话状态,产生系统的对话行为(dialog act),决定下一步做什么;dialog act 即表示观测到的用户输入( NLU 功能),以及系统的反馈行为(DA -> Response, NLG功能)
对话状态是一种从对话文本中抽取得到的数据结构。
对话状态追踪旨在自动化地从多轮对话文本中提取(槽,槽值)对集合,追踪这些槽值的动态变化,最终得到结构化的对话信息。
基于固定本体的方法(ontology-based methods):假定候选槽值已知,将对话状态追踪问题建模为分类问题
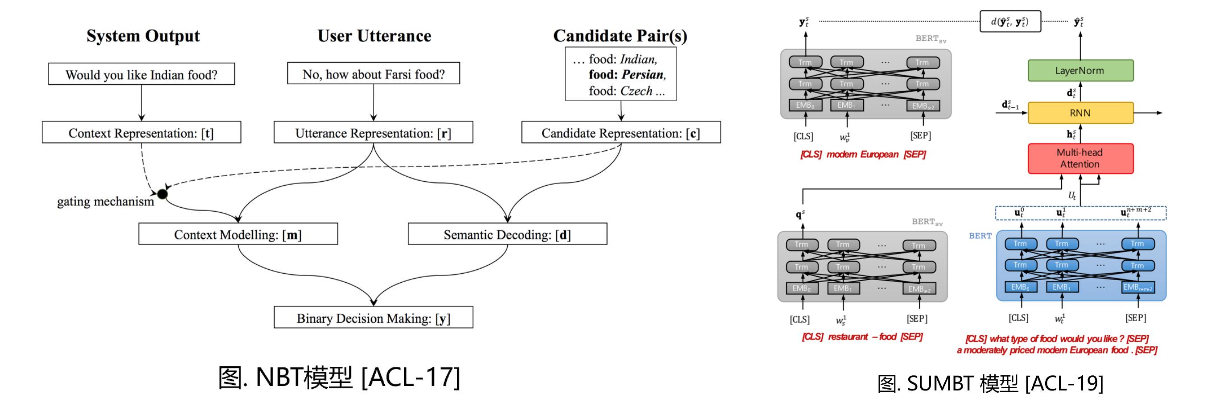
基于开放词表的方法(open-vocabulary based methods):假定候选槽值未知,将对话状态追踪问题建模为生成问题
三种解码生成的方式
(a)序列解码(逐步产生所有槽值)
(b)本体提示解码(给定槽名)
(c)自然语言提示解码(给定槽的描述信息)

对话策略学习:决定对话代理应采取哪些行动来有效实现特定目标。具体地,给定对话状态,要求对话系统选择合适的对话动作
建模方式:
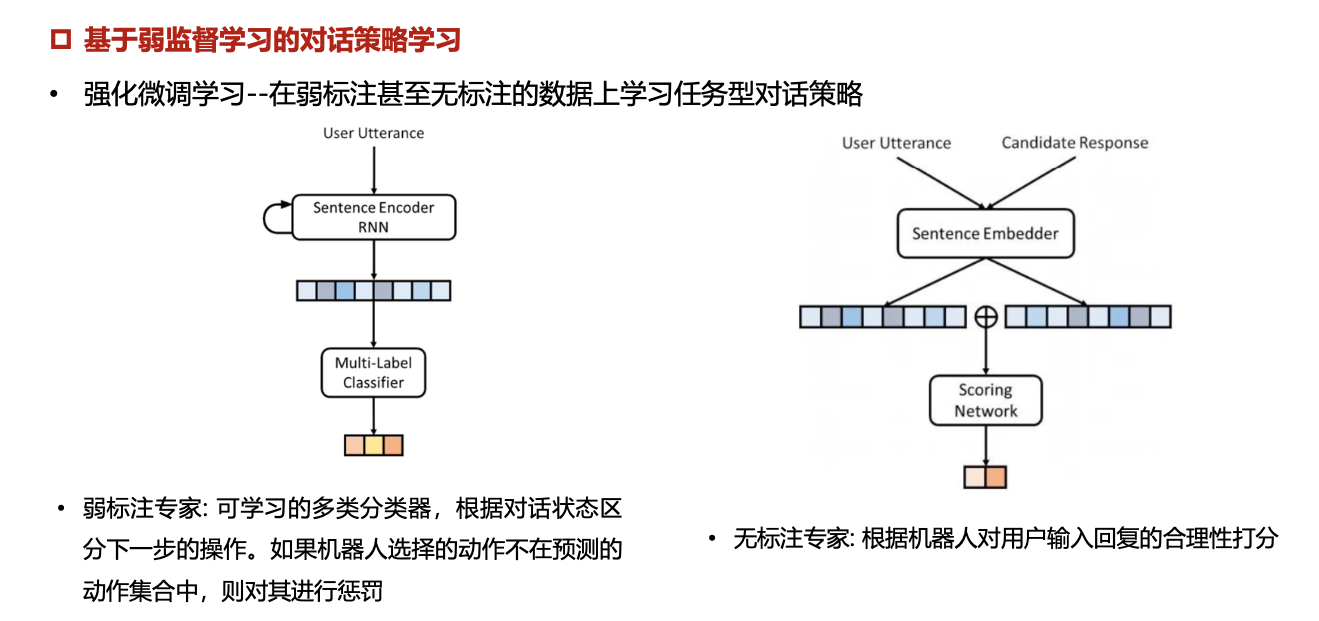
监督学习:利用已有的对话数据集,构建样本集(state, action),直接学习从系统状态到系统输出动作的映射
强化学习:在学习过程中,用户被当作环境,对话系统则作为个体(agent),系统的动作是生成回应。环境和系统进行多次交互(决策),奖励信号则可以是用户反馈的满意度或任务完成情况
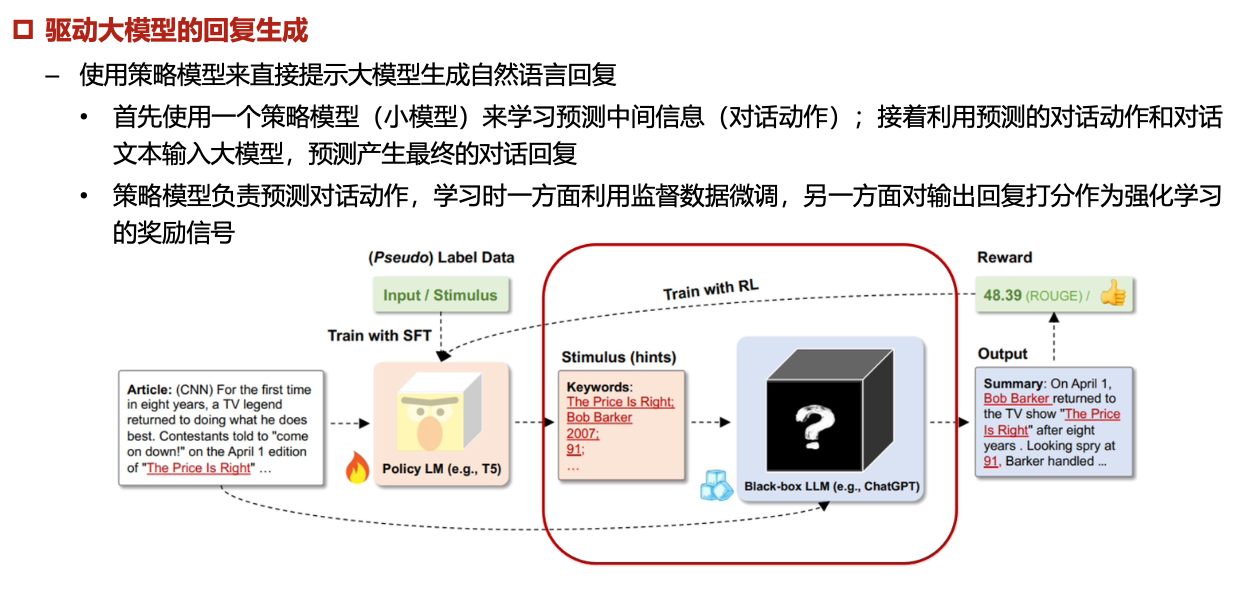
强化学习与监督学习结合:通过使用监督学习来预训练策略模型,然后使用强化学习对策略模型来进行微调和优化

自然语言生成模块
从对话动作到自然语言语句的映射,即从结构化数据到非结构化数据的映射
自然语言生成实现主要步骤
- 文本规划:生成句子得语义帧序列
- 句子规划:生成关键词、句法等结构信息
- 表层规划:生成辅助词及完整的句子
挑战
任务导向的对话规划: 任务型对话系统需要能够有效地规划对话流程,理解用户的任务意图,并在对话中引导用户朝着完成任务方向前进。然而,目前大模型的相关能力还在挖掘探索中
特定领域对话适配: 在某些领域或特定任务的对话中,难以获取大规模标注数据。大模型难以在领域数据进行有效微调,领域适配能力有待加强
领域知识更新和利用: 任务型对话系统需要能够及时更新知识(数据库),以反映现实世界或专业领域的知识变化。如何将领域知识融合到端到端大模型中有待讨论
