

《FirmAgent: Leveraging Fuzzing to Assist LLM Agents with IoT Firmware Vulnerability Discovery》
这篇论文《FirmAgent: Leveraging Fuzzing to Assist LLM Agents with IoT Firmware Vulnerability Discovery》的核心目标,是解决 IoT 固件漏洞挖掘里一个长期很难同时兼顾的问题:
静态分析覆盖广,但误报高;动态分析(尤其 fuzzing)能给出可触发样例,但漏报高。 作者提出的 FirmAgent,本质上是在这两者之间做了一个很“聪明”的分工:先让 fuzzing 负责“找到真实输入从哪里进来、程序运行时到底走了哪些调用关系”,再让 LLM 负责“沿着这些更可信的路径做语义级污点分析,并补全 PoC”。作者把它定位为第一个“用 fuzzing 来辅助 LLM agent 做 IoT 固件漏洞发现”的混合框架。
1. 论文到底在解决什么问题
IoT 固件漏洞挖掘里,尤其是跑 Linux 的路由器、摄像头这类设备,常见方法大致分三类:
第一类是静态分析。
比如 SaTC、EmTaint、HermeScan、OctopusTaint。这些方法不运行程序,只看二进制/反编译代码,优点是理论上能“看遍很多路径”,缺点是很容易把不是真正外部可控的输入点也当成 source(污点源),于是误报很多;而且它们通常只能报“可能有洞”,不给 PoC,后续还要人手工验证。
第二类是动态分析 / fuzzing。
比如 FirmAFL、Greenhouse、FirmFuzz。这类方法的优点是,只要真打到了漏洞,通常就能给出 crash、输入样例,甚至直接给 PoC;问题是 IoT 固件路径约束很重,很多分支依赖特定 URI、参数名、配置项甚至硬件状态,fuzzer 很难靠随机变异跨过去,于是大量 sink 根本到不了,造成漏报。
第三类是混合方法。
传统 hybrid fuzzing 的想法是边 fuzz 边做符号执行/约束求解/甚至让 LLM 帮忙生成能过检查的输入。但在 Linux-based IoT firmware 上,这样做的代价很大:
一方面运行在模拟环境里的约束收集不稳定;
另一方面 IoT 固件特别容易崩、模拟又不完整,把 LLM 放进 fuzzing 内环会让系统很重、很脆。
这篇论文的关键点在于:它不是把 LLM 放进 fuzzing 的在线决策环里,而是把 fuzzing 当成“动态事实收集器”,把最难、最容易错的那部分事实先收上来,然后交给 LLM 去做更精准的静态推理。 这点非常重要。
2. 作者的核心观察:为什么这条路线是成立的
论文最有价值的不是“用了 LLM”,而是它先做了一个非常关键的经验观察。
2.1 静态分析为什么误报高
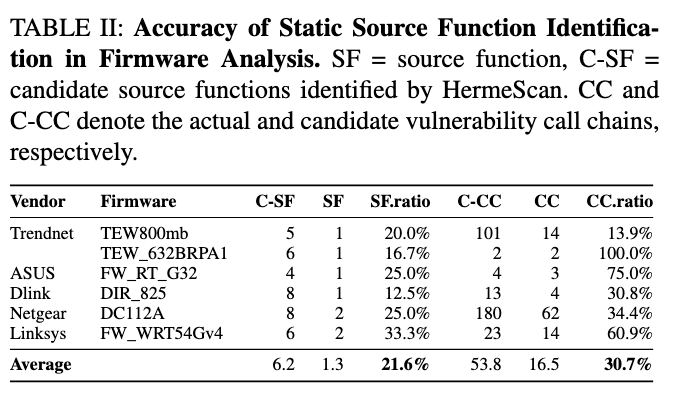
表 II 里统计了静态 source 识别的准确性。以 HermeScan 为代表的静态方法,虽然已经算当前比较准的,但它找到的候选 source function 里,平均只有 21.6% 真的是实际接收外部输入的 source。
进一步看,由这些候选 source 拼出来的候选调用链,只有 30.7% 是真实漏洞调用链。这就解释了为什么静态分析会报一堆“看上去能通,实际上不可控”的假漏洞。
2.2 fuzzing 为什么漏报高
表 III 更关键:
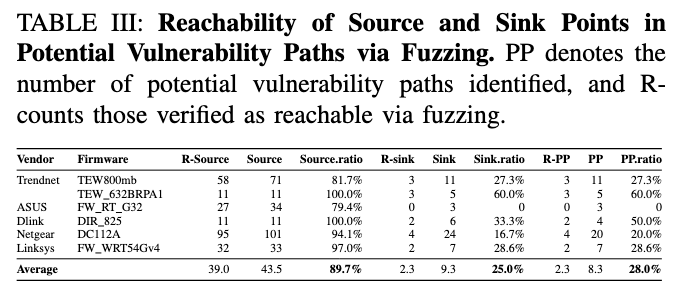
作者发现 fuzzing 在这些固件上,平均能到达 89.7% 的 source 点,但只能到达 25.0% 的 sink 点。
这说明一个很有意思的事实:
- 外部输入进入程序的位置通常比较浅,fuzzing 比较容易摸到;
- 但从 source 再走到危险 sink,中间会经过很多复杂条件,比如 URI 匹配、配置项判断、字符串格式检查、状态依赖,导致 fuzzer 很难真正触发漏洞。
所以作者的洞察是:
让 fuzzing 干它擅长的事:确认“这里真有外部输入进来”;
让静态/LLM 分析干它擅长的事:从这些可信 source 往后把路径推到底。
这就是 FirmAgent 的理论基础。
2.3 两个具体例子特别能说明问题
例子一:静态分析会被间接调用卡住
图 1 展示了 Trendnet 路由器里的一个例子。
 请求匹配到
请求匹配到 NTPSyncWithHost.cgi 后,会通过函数指针跳到 sub_F934。在这个函数里,用户输入经过一些字符串处理,最后进入:
sprintf(v5, "date -s %s", url_remove);
system(v5);这显然是潜在命令注入路径。
问题是:静态分析很难把“间接调用点”和真正被调到的目标函数”准确连起来,于是污点在函数指针处“断掉了”,导致漏报。
而 fuzzing 在运行时是能看到“这次函数指针实际跳到了哪儿”的,所以它能补上这条控制流边。
例子二:fuzzing 会被配置条件卡住
图 2 里 Netgear DC112A 的代码:

这里 deviceName 是外部输入,但想走到 system,还得满足固件内部配置条件。
fuzzer 可以把污点送进 Name,但未必能猜中 nvram 条件,所以动态上触发不到漏洞。
而如果你已经知道 Name 是真实外部输入,那么静态/LLM 就可以在后半段继续推理:只要某个配置成立,这里就有命令注入风险。
这两个例子恰好说明:
静态分析最怕 source 不准、间接调用断链;动态分析最怕深路径条件。
FirmAgent 就是在这两个薄弱点之间做拼接。
3. FirmAgent 的总体结构
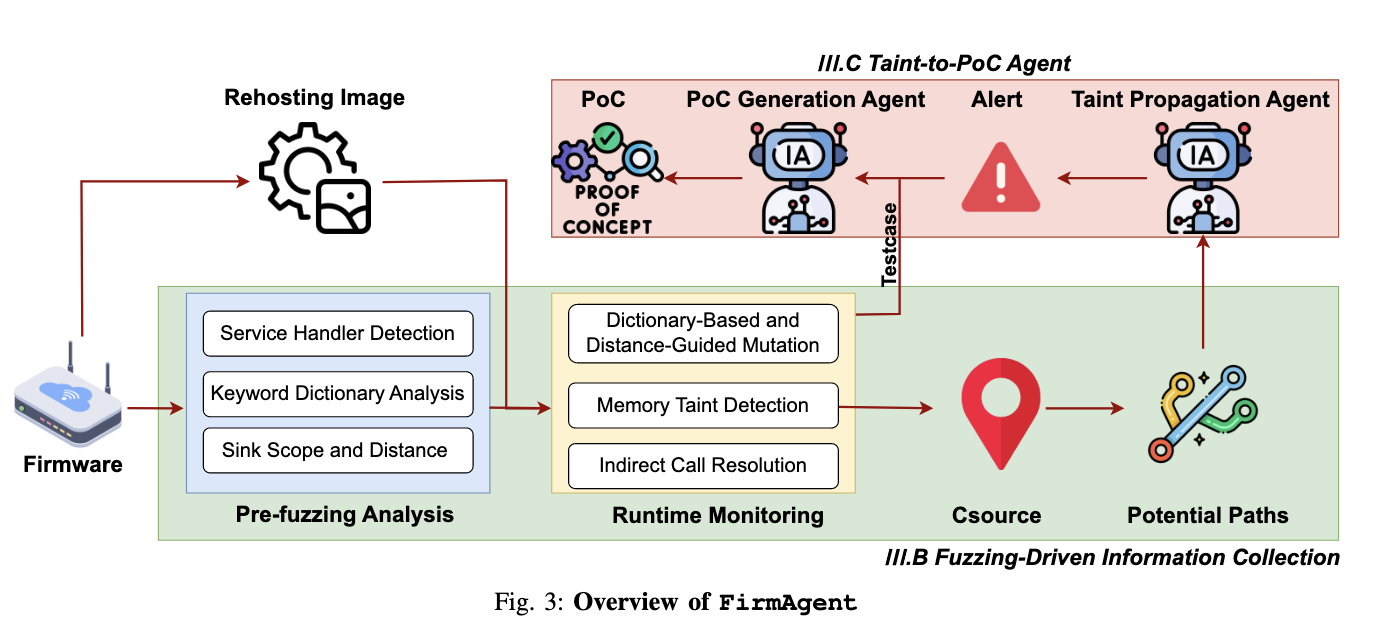
阶段一:Fuzzing-Driven Information Collection
即“fuzzing 驱动的信息收集”。
目标不是立刻找到漏洞,而是先收三类对后续分析最关键的信息:
- 真实 source 点 / Csource:程序里哪些位置在运行时真的接收了外部输入;
- 更完整的调用图:尤其是通过运行时解析补全的间接调用;
- 可达测试样例:哪些请求模板至少能走到这些 source 点。
阶段二:Taint-to-PoC Agent
即“从污点到 PoC 的 agent 阶段”。
在拿到上面的动态事实以后,再做两件事:
- 污点传播 agent:沿着从 Csource 到 sink 的潜在路径,做语义级污点分析;
- PoC 生成 agent:把 fuzzing 收集到的“可达 testcase”与 LLM 推导出的“语义约束”结合,自动补出一个真正能触发漏洞的 PoC。
这两个阶段的组合,实质上是:
动态阶段负责“把问题缩小到真实、可信的范围”
LLM 阶段负责“在这个可信范围里做高层语义推理和样例补全”
这比“全靠静态猜 source”,或者“全靠 fuzzing 硬撞 sink”,都要稳得多。
4. 第一阶段:Fuzzing 驱动的信息收集,具体是怎么做的

4.1 预分析(Pre-fuzzing Analysis)
这是正式 fuzz 之前的静态准备工作,主要做三件事。
4.1.1 Service Handler Detection:找服务处理函数
IoT 固件里的 web 服务通常有很多 handler,分别处理不同 URI、SOAP 操作、HANP 消息等。
问题是很多 handler 并不在前端页面里显式暴露,或者文档不完整。如果你不知道 URI,fuzzing 连入口都进不去。
作者的做法是:
- 从公开接口信息里抽取初始请求模式
例如 web server 配置、SOAP 定义、API 文档; - 利用字符串引用和控制流分析,找到这些请求对应的 handler 代码块;
- 再收集这些 handler 附近的上下文,
- 交给 LLM 去学习“handler 长什么样”;
- 通过代码结构相似性,挖出未文档化的 handler。
这个设计的意义在于:
不是只 fuzz 前端表面暴露的接口,而是尽量把隐藏后端接口也纳入覆盖范围。
4.1.2 Keyword Dictionary Analysis:构建关键字字典
传统方法像 SaTC,很依赖前端-后端共享关键字匹配。但这样会漏掉“只有后端才知道”的参数名。
FirmAgent 想要更系统地提取参数关键字。
它的方法是:
- 先通过人工与重宿主后的固件交互,拿到一些初始网络流量 seed;
- 用这些 seed 去分析二进制,找哪些函数和这些关键字交互频繁;
- 过滤掉通用字符串函数,如
strcpy、strcmp; - 选出最可能处理参数的候选函数;
- 对这些函数的实参做回溯,提取参数名。
这里回溯参数来源时,论文总结了几种典型模式。

主要包括:
- 直接硬编码字符串:例如
get_cgi("countdown_time") - 变量由字符串常量赋值而来
- 变量来自
.data段数组或全局结构 - 变量通过
sprintf/strcat等动态拼接生成
这一步产出的不是“漏洞”,而是一个用于 fuzzing 的参数字典。后面生成请求时,哪些字段值得替换、替换成什么,就靠它。
4.1.3 Sink Scope and Distance:找 sink 范围并计算距离
这一步是为了让 fuzzing 更有方向感。
作者先通过模式匹配,把固件里一类一类安全敏感 API 找出来,作为 sink。
比如命令执行、拷贝、格式化字符串之类,分别对应命令注入、缓冲区溢出等风险。
然后做两件事:
第一件:算出哪些基本块“可能通向 sink”
对每个 sink 做向后可达性分析,得到一片和 sink 有关的地址范围。
后面 QEMU 只在这个范围里重点做监控,这样能大幅减轻开销。
第二件:给基本块打“离 sink 远近”的分数
作者在第 7 页给了一个公式:
$$
score(n)=depth(n)+w\cdot dis(s)
$$
其中:
depth(n):基本块在 CFG 里的结构深度;dis(s):到最近 sink 的最短距离;w:权重。
这个分数后面会用来指导 seed 排序和参数变异。
你可以把它理解成:既考虑路径深入程度,也考虑和危险点的接近程度。
4.2 运行时阶段(Runtime Monitoring)
预分析做完后,真正开始在用户态重宿主环境里跑 fuzzing。这里也分两部分。
4.2.1 变异策略:不是乱变,而是“字典 + 距离引导”
作者强调,传统 bit flip、splicing 在固件 web 二进制上效果不够好,因为 source 和 sink 大多都在服务 handler 附近。
所以它们采用 dictionary-based + distance-guided 的灰盒 fuzzing:
- 用之前提取的 URI 和关键字字典构造请求模板;
- 系统化地替换参数值,注入可能恶意的 payload;
- 每个关键字还会带上定制 taint tag,这样后面更容易跟踪它是否经过消毒;
- 运行时记录执行过的基本块;
- 根据基本块对应的预计算分数,给 testcase 打分;
- 高分种子优先继续变异,低分样例则尝试替换成别的关键字。
它的目标不是“尽快撞出 crash”,而是尽可能覆盖更多 handler,找到更多真实输入点 Csource。
4.2.2 运行时信息收集:如何识别 Csource 和间接调用
这是这篇论文最关键的工程点之一。
作者在 QEMU 的 TCG 执行阶段做了选择性插桩,但不是全程序都插,而是只盯着前面算出来的 sink scope。
在这个范围里,每执行一条相关指令,就检查内存状态是否从untainted 变成 tainted。
如果某个内存位置在这里第一次出现这种变化,就把对应地址记为 Csource。
这个定义很重要。
FirmAgent 里的 Csource 不是“静态上猜测的 source function”,而是:
运行时真实观察到、受到外部输入影响、并且出现在安全敏感范围内的代码点。
所以它比传统静态 source 精确得多。
同时,系统还会记录间接调用的真实目标。
做法是给基本块加轻量回调,识别间接跳转/调用,记录 (caller, callee) 对。
这样就能把静态看不清的函数指针调用在运行时补全进调用图里。
最后,利用:
- 当前得到的
Csource - 完整得多的
CallGraph - 预定义的
Sinks
就可以构造出一批 Potential Paths(潜在漏洞路径)。
4.3 算法 1 如果用白话说,流程就是
第 6 页算法 1 可以翻成下面这件事:
- 从固件里提取 handler、关键字、sink、静态调用图;
- 反向分析得到 sink 相关范围和距离图;
- 启动模拟器;
- 依次把请求模板中的 URI 替换成每个 handler;
- 再把关键字逐个注入到模板里;
- 根据距离信息引导变异;
- 执行变异后的请求;
- 如果在 sink scope 里观察到 taint,就记录该位置为 Csource,并保存 testcase;
- 同时收集所有运行时出现的间接调用目标;
- 用更新后的调用图,持续生成从 Csource 到 sink 的潜在路径。
所以,fuzzing 在这里不只是“找 crash”,而是在持续在线地产生静态分析更需要的先验事实。
5. 第二阶段:Taint-to-PoC Agent,怎么把“潜在路径”变成“真实漏洞”
到了这一阶段,FirmAgent 已经有了:
- 哪些点是真 source(Csource)
- 哪些路径从这些点能走到危险 sink
- 哪些请求样例至少能到 source
接下来才轮到 LLM 上场。
5.1 先修反编译结果:LLM-Based Refinement
作者非常清楚地意识到:
如果直接把 IDA 的反编译结果喂给 LLM,LLM 也会被“垃圾输入”带偏。
因为 IDA 在固件二进制上常常会出现:
- 漏参数
- 漏返回值赋值
- 控制流/数据流恢复不准
附录给了一个特别直观的例子。

原始 IDA 结果里,get_cgi("date") 的返回值根本没被保留下来,这显然丢失了关键数据流。
而 LLM refinement 后,代码被恢复成更合理的形式:这样污点从 date 到 system(command) 的关系才真正可见。
所以这一层实际上是在做先把反编译代码变得更“可推理”,再做污点分析。
5.2 污点传播 Agent:LLM 具体怎么分析

它会把以下信息交给 LLM:
- 当前函数的反编译代码
- 相关 source
- 相关 sink
然后让它判断:
source 的数据能否传播到 sink,并构成漏洞。
如果中间遇到未知函数,LLM 会先停下来,要求系统补上这些函数的反编译代码,再继续分析。
这就形成了一种“交互式函数级分析”。
这个分析怎么跨函数?
论文说它是函数级做的。
- 如果 source 和 sink 在同一函数里,就做函数内污点传播;
- 如果不在同一函数里,就先在调用点找出“哪些参数已被 taint”,
- 再把这些 tainted 参数当成被调函数里的新 source,
- 一层一层递归下去,直到走到 sink。
这实际上就是LLM 驱动的跨过程污点传播。
5.3 作者还专门处理了 LLM 容易犯错的三类误报
他们发现,LLM 做固件污点分析时,最容易在三种地方出错。附录第 16 页 图 11 给了很好的例子。
第一类:没看懂 sanitizer
例如有个输入 Value,程序逐字符检查,只允许数字;一旦有非法字符就 exit(1)。
虽然最后确实有:
sprintf(v5, "'%s'.gif '%s'.txt", Value, Value);
system(v5);但因为输入早已被严格限制成数字,这其实不构成可利用命令注入。
如果 LLM 只看见 system(v5),很容易误报。
第二类:把“只参与条件判断”的 taint 当成真正传播
例如:
if (!strcmp(taint, "2"))
v4 = "factory_hm info fat 2";
else
v4 = "factory_hm info fat 1";
system(v4);这里 taint 只决定分支,不直接流入 sink 参数。
sink 真正执行的永远是常量字符串。
这不是可控命令注入。
第三类:把系统文件读出来的数据当成用户输入
例如从 /etc/passwd 读数据进 buf,再 system(buf)。
这虽然“数据进入了 sink”,但来源不是用户可控输入,因此不属于作者关心的 taint-style 漏洞。
为了解决这些误报,论文在 taint agent 之后又加了一个 alert verification module,用 few-shot prompt 去专门甄别这几类情况。
另外还做了 function-level caching,避免多个调用链重复分析同一个函数。
5.4 PoC Generation Agent:怎么把“能到 source 的 testcase”补成“能打中 sink 的 PoC”
这是这篇论文实用性非常强的一部分。
传统静态分析最麻烦的地方就在这里:
它只能说“这里可能有洞”,但不会告诉你输入到底要怎么构造。
验证人员只好自己去读代码、猜参数、写 PoC,成本很高。

FirmAgent 的思路是:
- 在污点传播阶段,顺手提取语义约束
比如:- 必须走哪个分支
- 某些参数必须等于什么
- 某些特殊字符会被过滤
- 某字段必须满足某种格式
- fuzzing 阶段已经有了一个至少能走到 source 的 testcase
- 把二者一起交给 PoC 生成 agent
prompt 里就包括:- Reachable test case
- Input validation constraints
- Decompiled code
然后让 LLM 去推断:
每个参数应该填什么值,才能既满足前置条件,又让 taint 真正传到 sink。
附录第 16 页 C 节说得更明确:
最终 PoC 是 HTTP 请求包。
比如 fuzzing 已经给了 URL、Header、Body 框架,LLM 负责补上关键字段值,例如:
NtpDstEnable = "1"NtpDstOffset = "A"*300
这样就能把“部分有效的请求模板”补成“真正能触发缓冲区溢出或命令注入的 PoC”。
这一步是 FirmAgent 和很多静态工作的最大差异之一:
它不只是报漏洞,而是尽量把验证工作也自动化了。
6. 实现细节:这不是概念模型,作者确实做了完整原型
第 9 页的实现部分给了不少工程信息:
- 总体实现量:4000+ 行 Python,1000 行 C
- 用 binwalk 解包固件 rootfs,定位 web 二进制
- 用 IDA Pro + 自定义 IDAPython 做预分析
- 用 Greenhouse 做用户态单服务重宿主
- 用 自定义 QEMU 插件 收集内存 taint 与间接调用
- LLM 选的是 DeepSeek-R1,温度设为 0.7
而且它是做成了一个全自动框架:
一旦 fuzzing 开始,系统就持续识别 Csource,把对应地址送去 taint propagation agent,再进入 PoC 生成。
换句话说,这不是“先 fuzz 半天,再人工挑一些点交给 LLM”,而是作者想把整个流程串成自动化流水线。
7. 实验部分:论文最重要的数据结论
7.1 数据集与对比对象
作者选了 14 个可成功模拟的真实 IoT 固件,来自:
- Netgear
- D-Link
- Tenda
- Trendnet
- Linksys
- ASUS
- TOTOLINK
对比工具包括:
- EmTaint(静态)
- HermeScan(静态)
- Greenhouse(动态)
- Hy-FirmFuzz(混合)
另外一些工具没纳入直接对比,原因也写得很清楚:
- SaTC:已有工作表明比不过 HermeScan/EmTaint
- LARA:不开源,无法复现
- Mango:和 HermeScan 同属 reaching definitions 路线,效果接近
- OctopusTaint:开源代码不完整,缺 source 识别等关键部件
实验环境也很豪华:
Xeon Platinum 8358,128 逻辑核,2TB 内存,Ubuntu 20.04,Docker 重复实验 4 次。
7.2 RQ1:FirmAgent 与 SOTA 相比到底强多少
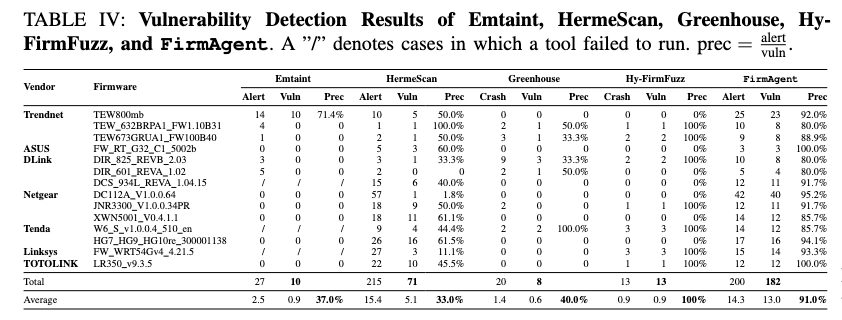
FirmAgent 的总体结果
- 200 个 alerts
- 其中确认出 182 个真实漏洞
- Precision = 91%
- 漏洞类型包括:
- 45 个命令注入
- 137 个缓冲区溢出
- 其中 140 个此前未知漏洞
- 27 个未知命令注入
- 113 个未知缓冲区溢出
- 17 个已经分配 CVE
对比基线
- EmTaint:27 alerts,10 real vulns,37% precision
- HermeScan:215 alerts,71 real vulns,33% precision
- Greenhouse:20 crashes,8 real vulns,40% precision
- Hy-FirmFuzz:13 crashes,13 real vulns,100% precision
也就是说:
- 比 EmTaint 多发现 18.2 倍
- 比 HermeScan 多发现 2.6 倍
- 比 Greenhouse 多发现 22.8 倍
- 比 Hy-FirmFuzz 多发现 14 倍
第 11 页 图 6 还画了一个漏洞包含关系图,非常直观:
FirmAgent 覆盖了其他工具发现的所有漏洞。

这说明它不是“找到另一批不同漏洞”,而是整体发现能力明显更强。
7.3 为什么别的工具不如它
论文对每个基线都做了具体误报/漏报分析。
EmTaint
- 误报来源:过度 aliasing,把不相关变量也 taint 了
- 还不太会识别程序内部 sanitizer
- 漏报来源:只支持预定义 source,很多固件自定义 source 没覆盖到;部分固件指令支持也有限
HermeScan
- 误报:source 识别不准、sanitize 处理不好
- 漏报:reaching definition 在复杂数据流下会丢 taint
Greenhouse
- 误报:有些 crash 其实是内存限制或 QEMU 模拟不完整,不是真漏洞
- 漏报:不知道隐藏 URI、参数字典,也过不去程序特定约束,很多 sink 根本测不到
Hy-FirmFuzz
- 优点:只要报出来,基本都是真的,所以没有误报
- 缺点:只测前端暴露的 URL 和参数,而固件里大量功能接口根本没暴露,漏报非常严重
FirmAgent 自己的误报来自哪里
作者也没有回避这个问题。
FirmAgent 的 18 个误报全部是缓冲区溢出,主要因为 LLM 有时推不准:
- 输入真实长度
- 目标 buffer 大小
- 全局变量和当前函数变量之间的关系
换句话说,命令注入上它更稳,缓冲区尺寸推理上还不够完美。
7.4 时间效率
从时间看:
- EmTaint 平均约 3 分钟
- HermeScan 平均约 8 分钟
- FirmAgent 每个固件设定 1 小时
- Hy-FirmFuzz 约 78 分钟
- Greenhouse 约 24 小时
所以 FirmAgent 确实比静态工具慢,但它换来了三样东西:
- 更高 precision
- 更低 false negative
- 自动 PoC 验证能力
而且作者强调,不同固件可以并行分析,所以总体吞吐还可以接受。
8. RQ2:用 fuzzing 找 source,真的可靠吗?
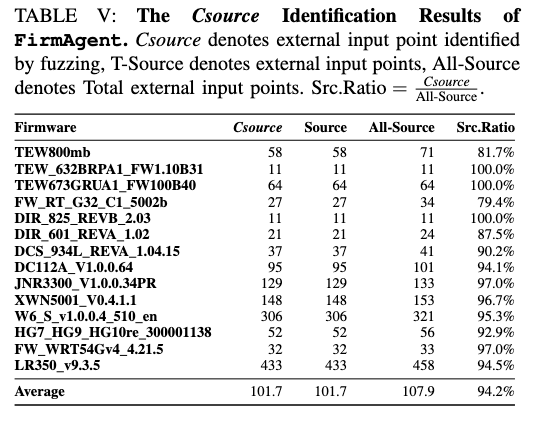
作者统计了:
Csource:FirmAgent 运行时识别到的 sourceSource:这些 Csource 中真实 source 的数量All-Source:人工验证得到的所有外部输入点总数
结论非常漂亮:
- Csource 的准确率是 100%
- 平均覆盖率是 94.2%
为什么准确率能 100%?
因为它不是靠字符串匹配猜,而是只在运行时真的观察到 taint 传播的地方才记 source。
这就从根上消掉了传统静态方法的“候选 source 假阳性”。
那剩下 5.8% 为什么没看到?
作者说主要有两类:
- 死代码 / 旧代码 / 实际不可达路径
这些本来就不会被执行,不看到反而有助于减少误报。 - 跨过程很深的路径
某些 source 要满足早期复杂条件才会出现,fuzzing 没走到。
但论文还说,这并没有导致真正的漏洞漏掉,因为后续 LLM 在分析调用链时,会把这些 source function 补充当成 source 来继续推理。
这点很重要:
FirmAgent 用 fuzzing 确认 source,是为了尽可能降低误报;但它并没有把 LLM 死死限制在“只分析动态看到的那些点”。
这让它在 precision 和 recall 之间取得了比较好的平衡。
9. RQ3:消融实验说明各模块到底有多重要
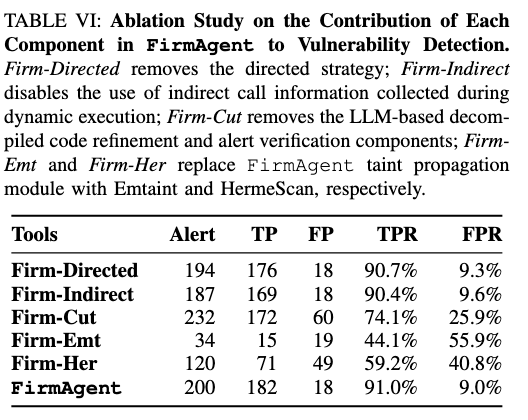
9.1 去掉定向 fuzzing(Firm-Directed)
结果变成:
- 194 alerts
- 176 true positives
- 少了 6 个真实漏洞
说明定向 fuzzing 的价值在于:
它能把探索推向更深的 source 点,而不是只在浅层打转。
9.2 去掉间接调用解析(Firm-Indirect)
结果变成:
- 187 alerts
- 169 true positives
- 少了 13 个真实漏洞
这直接证明:
运行时补全函数指针/间接调用的控制流边,是发现这类固件漏洞的关键。
9.3 去掉 LLM refinement 和 alert verification(Firm-Cut)
结果变成:
- 232 alerts
- 172 true positives
- 60 false positives
也就是说:
- 真漏洞少了 10 个
- 假阳性多了 42 个
这说明前面那两层“看起来像辅助功能”的模块,其实非常重要:
- refinement 负责修复反编译缺陷,减少污点丢失
- verification 负责识别 sanitizer / 非传播 taint / 系统文件来源,减少误报
9.4 用传统 taint 引擎替代 LLM taint agent
- Firm-Emt:34 alerts,15 TP,19 FP
- Firm-Her:120 alerts,71 TP,49 FP
这说明,即便把 source 识别换成 FirmAgent 的动态 Csource,传统 taint 分析依然不够好。
所以提升不是只来自“source 找准了”,还来自 LLM 的语义级污点推理能力。
10. RQ4:自动生成的 PoC 到底有没有用
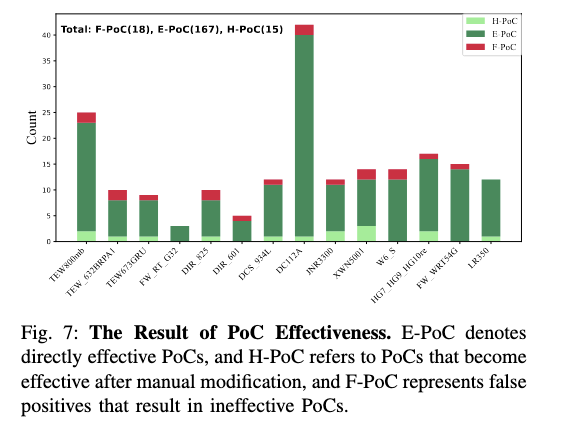
作者把 PoC 分成三类:
- E-PoC:不做任何人工修改,直接就能在真实设备上触发
- H-PoC:稍微人工调整后能触发
- F-PoC:根本触发不了,属于误报
结果是:
- 总共 200 个 alerts
- 18 个是误报,对应 F-PoC
- 剩下 182 个真实漏洞里:
- 167 个 PoC 直接有效
- 15 个稍微人工改一下就有效
所以直接有效率是 91.8%。
为什么那 15 个不能一步到位?
作者说大多是命令注入,原因在于 payload 形式非常依赖上下文。
比如某些固件做了黑名单过滤,不让用 ;、|、&,但过滤又不完整,需要安全研究人员根据具体命令上下文设计绕过 payload。
这类事情 LLM 目前还不够稳定。
但即便如此,这个结果已经很强了。
因为传统静态工具通常0% 自动 PoC 能力,而 FirmAgent 已经把绝大部分验证工作省掉了。
11. 这篇论文真正有价值的地方,我认为有四点
第一,它提出了一个很清晰的“职责分离”思想
不是让 fuzzing 和 LLM 都做所有事,而是让每个组件只做自己最擅长的部分:
- fuzzing:确认真实输入点、补全动态调用事实、提供可达输入骨架
- LLM:做语义级污点传播、识别 sanitizer、推断参数约束、补全 PoC
这种分工比“全静态”或“全动态”都更现实。
第二,它重新定义了 fuzzing 在固件分析里的价值
这里 fuzzing 不再只是“撞漏洞的锤子”,而是变成了:
- 真实 source 的判定器
- 间接调用的运行时解析器
- PoC 的模板生产器
这是一种很漂亮的角色转换。
第三,它把 LLM 用在了更适合它的位置
LLM 最强的不是算地址,而是理解语义、补全缺失上下文、推断“如果要触发这个条件,输入大概要长什么样”。
FirmAgent 让 LLM 去干的正好是这些事,而不是让它在 fuzzing 内环里频繁实时生成变异。
第四,它非常强调“能验证”
安全研究里,只报 alert 而不给 PoC,实际价值会打折。
FirmAgent 的 PoC 生成模块让这个工作更接近真实漏洞挖掘流程,而不是停留在“静态告警系统”层面。
12. 论文的局限,作者也讲得比较诚实
12.1 依赖重宿主能力
第 12-13 页讨论部分说得很明确:
FirmAgent 的能力高度依赖底层 rehosting 框架,尤其是 Greenhouse。
而 Greenhouse 目前的限制包括:
- 新固件成功率还不高
- 只能做单服务重宿主
- 所以只能分析那个服务对应的单个 binary
- 对跨 binary、多服务协同漏洞无能为力
这意味着:
FirmAgent 很强,但它的适用面,仍然受制于“固件能不能被稳定跑起来”。
12.2 缓冲区溢出判断仍然会有 LLM 误差
作者明确指出,目前的大部分误报都来自 buffer overflow。
因为 LLM 对:
- 精确内存尺寸
- 全局变量影响
- 输入长度与目标 buffer 的真实关系
理解还不够稳定。
他们提出未来可以用:
- 更精确的数据建模
- RAG
- 微调
来增强这部分能力。
12.3 从我的角度再补一条
论文虽然结果很好,但实验样本是 14 个固件。
对于 NDSS 论文来说,这个规模已经不算小了,尤其考虑到需要可模拟、可重宿主、可真实验证,但如果从“通用工业能力”角度看,仍然离大规模普适部署有距离。
也就是说,这篇论文更像是在证明:
这条技术路线是对的,而且非常有前景。
而不是说“今天起所有 IoT 固件都能自动挖得很好”。
13. 如果把整篇论文压缩成一句话
这篇论文最核心的思想可以概括成:
不要让 LLM 去猜哪个输入是真的用户可控,也不要让 fuzzing 去硬撞所有复杂条件;
先用 fuzzing 把“真实输入点”和“真实运行时控制流”找出来,再让 LLM 沿着这些更可信的路径做污点分析和 PoC 补全。
这就是它为什么能同时把:
- 静态分析的误报
- 动态分析的漏报
- 手工验证的成本
一起压下去。